--- ext/curses/curses.c Tue Nov 11 12:00:39 2008
+++ ext/curses/curses.c Sun Dec 21 17:00:44 2008
@@ -410,6 +410,9 @@
static VALUE
curses_getch(VALUE obj)
{
+#if defined(__sun)
+ eucwidth_t wp;
+#endif
int c;
rb_read_check(stdin);
@@ -416,7 +419,12 @@
curses_stdscr();
c = getch();
if (c == EOF) return Qnil;
+#if defined( __sun)
+ getwidth(&wp);
+ if (ISPRINT(c, wp)) {
+#else
if (ISPRINT(c)) {
+#endif
char ch = (char)c;
return rb_locale_str_new(&ch, 1);
@@ -1105,12 +1113,20 @@
{
struct windata *winp;
int c;
+#if defined(__sun)
+ eucwidth_t wp;
+#endif
rb_read_check(stdin);
GetWINDOW(obj, winp);
c = wgetch(winp->window);
if (c == EOF) return Qnil;
+#if defined(__sun)
+ getwidth(&wp);
+ if (ISPRINT(c, wp)) {
+#else
if (ISPRINT(c)) {
+#endif
char ch = (char)c;
return rb_locale_str_new(&ch, 1);
Sonntag, 21. Dezember 2008
Ruby 1.9.1 Preview2 selberbacken
Im Moment spiele ich mal wieder mit diversen Skriptsprachen herum von denen eine Ruby ist. Leider läßt sich der aktuelle Preview nur mit ein paar Umwegen unter OpenSolaris backen. Darum hier ein kleines Patch damit Vorgang durchläuft. Ich übernehme wie immer keine Verantwortung für eventuelle Probleme ^^.
Sonntag, 14. Dezember 2008
Aktivismus: "The Yes Men"
Ich bin heute über einen sehr interessanten Link gestolpert der ausnahmsweise mal nichts mit Technik zu tun hat. Wirklich sehr sehenswert: The Yes Men
Schon krass was man unter dem Motiv der Gewinnmaximierung den Leuten alles verkaufen kann...
Schon krass was man unter dem Motiv der Gewinnmaximierung den Leuten alles verkaufen kann...
Samstag, 13. Dezember 2008
Nahtloses 64-Bit
Mir fallen immer wieder Fragen auf die sich auf die 64-Bit Fähigkeit von OpenSolaris beziehen. Wie z.B. "Wo krieg ich die 64-Bit ISO?" oder "Unterstützt Solaris das überhaupt?".
Ja, Solaris baut sich je nach vorliegender Architektur passend zusammen (ein Vorteil der durch die hohe Modularisierung möglich ist), soll heißen: Die OpenSolaris Installations CD ist beides (bootet als LiveCD afaik aber nur im 32-bit Modus). Um herauszufinden ob die eigene Solarisinstallation auch 64-Bit unterstützt reichen folgende Befehle:
Mein System unterstützt also i386 und amd64 und die Kernelkomponenten nutzen das 64-Bit Instruktionsset. Ich kann nahtlos 32 und 64-Bit Programme miteinander mischen ohne das ich irgendwas besonderes dafür tun muss (der Grund warum es auf 64-Bit Solaris Systemen auch schon seit Ewigkeiten die Möglichkeit gibt Flash zu nutzen), es läuft einfach.
Ja, Solaris baut sich je nach vorliegender Architektur passend zusammen (ein Vorteil der durch die hohe Modularisierung möglich ist), soll heißen: Die OpenSolaris Installations CD ist beides (bootet als LiveCD afaik aber nur im 32-bit Modus). Um herauszufinden ob die eigene Solarisinstallation auch 64-Bit unterstützt reichen folgende Befehle:
$ isainfo
amd64 i386
$ isainfo -vk
64-bit amd64 kernel modules
Mein System unterstützt also i386 und amd64 und die Kernelkomponenten nutzen das 64-Bit Instruktionsset. Ich kann nahtlos 32 und 64-Bit Programme miteinander mischen ohne das ich irgendwas besonderes dafür tun muss (der Grund warum es auf 64-Bit Solaris Systemen auch schon seit Ewigkeiten die Möglichkeit gibt Flash zu nutzen), es läuft einfach.
Freitag, 5. Dezember 2008
Amilo gone wild
Seit einigen Wochen schlage ich mich schon mit meinem alten Amilo Pi1505 und OpenSolaris herum. Irgendwann hat es sich dazu entschlossen sich im Kreis zu drehen sobald es größere Mengen an Daten geschrieben oder gelesen hat. Wer sich für ein Tagebuch dieser Schnitzeljagd quer durch den Quellcode interessiert kann das Ganze auf defect.opensolaris.org nachlesen.
Lange Rede, kurzer Unsinn. Der Hund lag in der NCQ begraben. MDB lieferte mir folgende Werte:
Dieser Zustand ist allerdings recht beknackt. ahciport_pending_tags sagt uns das ein Kommando in Slot 0 noch aussteht, Slot 0 zeigt aber auf 0 was wiederum heißt: Nichts steht aus. Und da beißt sich die Katze in den Schwanz und die ankommende Anfrage dreht sich immer im Kreis.
Lösung dieses Problems ist es NCQ zu deaktivieren. Das geht über 2 Wege
Der erste geht über MDB. Wir booten dazu OpenSolaris mit der Kerneloption -kd. Das versetzt uns beim Bootvorgang sofort in den Debugger. Hier setzen wir folgenden Breakpunkt und gehen wie folgt vor:
Das deaktiviert NCQ und das Problem ist Geschichte.
Jetzt hat man allerdings nicht wirklich Lust jedesmal solche Klimmzüge zu machen und für sowas ist die /etc/system da mit der wir bestimmte Kernelvariablen einfach selber setzen können ohne etwas neu zu kompilieren. Um das oben genannte festzuschreiben braucht man nicht mehr als folgende Zeile an die /etc/system anhängen:
Des weiteren mag diese Kiste wohl den Bootsplash und den HCI1394 Treiber nicht, darum sollte man im Textmode booten und die Bootoption -B disable-hci1394=true anhängen. So gibt dann auch endlich mein Sorgenkind Ruhe ;)
Lange Rede, kurzer Unsinn. Der Hund lag in der NCQ begraben. MDB lieferte mir folgende Werte:
uint32_t ahciport_pending_tags = 0x1
...
struct sata_pkt *[32] ahciport_slot_pkts = [ 0, 0, 0, 0, 0, usw.
Dieser Zustand ist allerdings recht beknackt. ahciport_pending_tags sagt uns das ein Kommando in Slot 0 noch aussteht, Slot 0 zeigt aber auf 0 was wiederum heißt: Nichts steht aus. Und da beißt sich die Katze in den Schwanz und die ankommende Anfrage dreht sich immer im Kreis.
Lösung dieses Problems ist es NCQ zu deaktivieren. Das geht über 2 Wege
Der erste geht über MDB. Wir booten dazu OpenSolaris mit der Kerneloption -kd. Das versetzt uns beim Bootvorgang sofort in den Debugger. Hier setzen wir folgenden Breakpunkt und gehen wie folgt vor:
::bp ahci`ahci_attach
::cont
....
sata`sata_func_enable/W 5
::cont
Das deaktiviert NCQ und das Problem ist Geschichte.
Jetzt hat man allerdings nicht wirklich Lust jedesmal solche Klimmzüge zu machen und für sowas ist die /etc/system da mit der wir bestimmte Kernelvariablen einfach selber setzen können ohne etwas neu zu kompilieren. Um das oben genannte festzuschreiben braucht man nicht mehr als folgende Zeile an die /etc/system anhängen:
set sata:sata_func_enable = 5
Des weiteren mag diese Kiste wohl den Bootsplash und den HCI1394 Treiber nicht, darum sollte man im Textmode booten und die Bootoption -B disable-hci1394=true anhängen. So gibt dann auch endlich mein Sorgenkind Ruhe ;)
Wireless LAN auf dem Thinkpad SL500
Ich habe mir ja vor einiger Zeit ein Thinkpad SL500 zugelegt um es mit OpenSolaris zu bestücken, seltsamerweise wurde der WLAN Chip (Intel 5100 AGN) allerdings nicht erkannt obwohl der Treiber bereits seit einigen Wochen bereitsteht. Naja, so seltsam dann auch wieder nicht. Es fehlte einfach die Zuordnung zwischen ID und Treiber. Also erst mal herausfinden wie sich unser Chip zu erkennen gibt, dazu haben wir ja scanpci:
Jetzt nur noch die passenden Werte in die /etc/driver_aliases übertragen.
Viola, Wireless auf dem SL500 :)
pci bus 0x0002 cardnum 0x00 function 0x00: vendor 0x8086 device 0x4237
Intel Corporation PRO/Wireless 5100 AGN [Shiloh] Network Connection
CardVendor 0x8086 card 0x1211 (Intel Corporation, Card unknown)
STATUS 0x0010 COMMAND 0x0046
CLASS 0x02 0x80 0x00 REVISION 0x00
BIST 0x00 HEADER 0x00 LATENCY 0x00 CACHE 0x08
BASE0 0x00000000fe1fe004 addr 0x00000000fe1fe000 MEM 64BIT
MAX_LAT 0x00 MIN_GNT 0x00 INT_PIN 0x01 INT_LINE 0x05
Jetzt nur noch die passenden Werte in die /etc/driver_aliases übertragen.
# update_drv -a -i '"pciex8086,4237"' iwh
Viola, Wireless auf dem SL500 :)
Donnerstag, 4. Dezember 2008
Screencast: What's new in OpenSolaris 2008.11
Ein zwölfminütiger Screencast über einige der neuen Features die OpenSolaris 2008.11 zu bieten hat mit Schwerpunkt auf Desktopfunktionalitäten.
Dienstag, 2. Dezember 2008
OpenSolaris 2008.11 erschienen
Nach über 6 Monaten Wartezeit ist OpenSolaris 2008.11 nun auf www.opensolaris.com erhältlich und es hat sich eine ganze Menge verändert. Während der erste Release noch sehr rudimentär war hat sich diese Version dem Desktop sehr viel mehr angenähert. Aktuellere Software, mehr Treiber und vor allem sind große Lücken in der Liste der Applikationen gefüllt worden. Ein paar der Highlights werde ich hier auflisten, dennoch ist dies nur ein kleiner Teil von dem was sich wirklich alles getan hat. Noch mehr neues hat Glynn Foster aufgelistet.
Einführungen zu OpenSolaris Technologien gibt wie Dtrace, ZFS und Beadm gibt es auf diesem Blog ebenfalls zu finden.
Gnome 2.24
Mit dem neuen Release wurde jetzt auch Gnome auf den neusten Stand gebracht. Für den inzwischen typischen Solaris Look sorgt natürlich wieder das Nimbus Theme

Firefox 3 und Openoffice 3
Ebenfalls mit von der Partie sind der neuste Firefox und die allerneuste Version von OpenOffice


Timeslider
Eines der Highlights ist sicherlich Timeslider. Im 15 Minuten Abstand werden Snapshots erstellt. Über den Tag verteilt werden diese dann jeweils stündlich archiviert, sowie täglich und wöchentlich. Wenn es zu eng auf der Platte wird räumt Timeslider einfach auf (Snapshots nehmen lediglich den Unterschied zwischen Filesystem und dem archiviertem Zustand an Blöcken in Anspruch). Um die Snapshots selber kümmern sich im Hintergrund diverse SMF Services, es wird also nicht nur der eingeloggte Benutzer versorgt sondern alle gewünschten Filesysteme (sehr praktisch für die beliebte Aufgabe gelöschte Dateien wiederherzustellen ;) )


Packagemanager mit neuen Repositories
Zu dem überarbeiteten Paketmanager kommen jetzt auch zusätzliche Repositories welche unter anderem Developer Releases, Sicherheitsupdates oder Community Pakete zur Verfügung stellen.

Network Automagic
Network Automagic wurde einem kompletten Facelift unterzogen. Auch wurde die Funktionalität erweitert. WLAN läßt sich nun genauso unkompliziert verwalten wie auch mehrere Netzwerkschnittstellen (was bei der alten Version nicht wirklich der Fall war).
SunStudio und Dtrace
Mit SunStudio Express enthält OpenSolaris eine komplette Entwicklungsumgebung mit Netbeans und den Sun Compilern und Debuggern. Netbeans enthält jetzt ebenso eine grafische Oberfläche für Dtrace mit dem Namen D-Light. Dtrace selber hat über die letzten Monate ebenso einige Updates erhalten wie z.B. den IP-Provider zum tracen von Netzwerkstack Aktivitäten.

ZFS 13 mit L2ARC
Auch ZFS ist in der Version 13 enthalten und unterstützt jetzt auch die L2ARC von OpenStorage die es einem unter anderem ermöglicht die Vorteile von SSD und HDD Platten zu vereinen indem einige wenige SSD Platten (oder auch nur eine) als Cache vor viele HDD Platten geschaltet werden. Somit kann man die Zugriffsgeschwindigkeit von SSD nutzen aber hat die Speichermasse von kostengünstigen HDD Platten.
Viele neue Treiber und Pakete
Dazu sind viele neue Treiber gekommen, vor allem Intel Chipsätze jeder Art werden inzwischen sehr gut unterstützt. Gleiches gilt inzwischen für erste SD-Card Reader und auch einige Webcams. Sollte das dennoch nicht reichen gibt es zusätzliche freie Netzwerkkarten Treiber bei Freenic und Audiotreiber bei Open Sound.
Also, viel Spass ;)
Newslinks: Golem, Heise, Distrowatch, OSNews, OpenSolaris 2008.11: Das neue "Sonnensystem"
Einführungen zu OpenSolaris Technologien gibt wie Dtrace, ZFS und Beadm gibt es auf diesem Blog ebenfalls zu finden.
Gnome 2.24
Mit dem neuen Release wurde jetzt auch Gnome auf den neusten Stand gebracht. Für den inzwischen typischen Solaris Look sorgt natürlich wieder das Nimbus Theme

Firefox 3 und Openoffice 3
Ebenfalls mit von der Partie sind der neuste Firefox und die allerneuste Version von OpenOffice


Timeslider
Eines der Highlights ist sicherlich Timeslider. Im 15 Minuten Abstand werden Snapshots erstellt. Über den Tag verteilt werden diese dann jeweils stündlich archiviert, sowie täglich und wöchentlich. Wenn es zu eng auf der Platte wird räumt Timeslider einfach auf (Snapshots nehmen lediglich den Unterschied zwischen Filesystem und dem archiviertem Zustand an Blöcken in Anspruch). Um die Snapshots selber kümmern sich im Hintergrund diverse SMF Services, es wird also nicht nur der eingeloggte Benutzer versorgt sondern alle gewünschten Filesysteme (sehr praktisch für die beliebte Aufgabe gelöschte Dateien wiederherzustellen ;) )


Packagemanager mit neuen Repositories
Zu dem überarbeiteten Paketmanager kommen jetzt auch zusätzliche Repositories welche unter anderem Developer Releases, Sicherheitsupdates oder Community Pakete zur Verfügung stellen.

Network Automagic
Network Automagic wurde einem kompletten Facelift unterzogen. Auch wurde die Funktionalität erweitert. WLAN läßt sich nun genauso unkompliziert verwalten wie auch mehrere Netzwerkschnittstellen (was bei der alten Version nicht wirklich der Fall war).
SunStudio und Dtrace
Mit SunStudio Express enthält OpenSolaris eine komplette Entwicklungsumgebung mit Netbeans und den Sun Compilern und Debuggern. Netbeans enthält jetzt ebenso eine grafische Oberfläche für Dtrace mit dem Namen D-Light. Dtrace selber hat über die letzten Monate ebenso einige Updates erhalten wie z.B. den IP-Provider zum tracen von Netzwerkstack Aktivitäten.

ZFS 13 mit L2ARC
Auch ZFS ist in der Version 13 enthalten und unterstützt jetzt auch die L2ARC von OpenStorage die es einem unter anderem ermöglicht die Vorteile von SSD und HDD Platten zu vereinen indem einige wenige SSD Platten (oder auch nur eine) als Cache vor viele HDD Platten geschaltet werden. Somit kann man die Zugriffsgeschwindigkeit von SSD nutzen aber hat die Speichermasse von kostengünstigen HDD Platten.
Viele neue Treiber und Pakete
Dazu sind viele neue Treiber gekommen, vor allem Intel Chipsätze jeder Art werden inzwischen sehr gut unterstützt. Gleiches gilt inzwischen für erste SD-Card Reader und auch einige Webcams. Sollte das dennoch nicht reichen gibt es zusätzliche freie Netzwerkkarten Treiber bei Freenic und Audiotreiber bei Open Sound.
Also, viel Spass ;)
Newslinks: Golem, Heise, Distrowatch, OSNews, OpenSolaris 2008.11: Das neue "Sonnensystem"
Samstag, 29. November 2008
OpenSolaris in den HPC Top 500
Der erste OpenSolaris HPC ist in den Top 500 aufgetaucht und auf Platz 221 eingezogen. Bei dem guten Stück handelt es sich um ein Fujitsu System der Japan Aerospace Exploration Agency. Mehr dazu auf dem Sun HPC Blog.
Donnerstag, 27. November 2008
Compiz unter OpenSolaris
Und nun wieder mal was für die Kategorie "Cool aber nutzlos". Compiz ist nicht gerade ein Auswahlkriterium für mich wenn es um Betriebssysteme geht, aber es ist schon sehr hübsch anzuschauen. Darum habe ich mich mal hingesetzt und mein System etwas getrimmt.
Als erstes erstellen wir einfach eine xorg.conf. Xorg macht das automatisch wenn man als root Xorg -configure eingibt. Die erstellte config dann einfach nach /etc/X11/xorg.conf kopieren.
Nun haben wir folgendes Problem: Diese config verwendet als voreingestellte Beschleunigung EXA. Das ist auf meinem Intel Chip mehr als lahm und alles andere als weich und flüssig. Ein anderes Problem ist das in der Xorg Version von OpenSolaris die OffscreenPixmap Funktion per default aktiv ist, das sorgt für teilweise richtig eklige Grafikfehler. Also tragen wir folgendes in die Device Section ein:
Ok, jetzt einfach den X-Server neu starten und Compiz unter den visuellen Effekten aktivieren. Und voila: Es wird prollig ;)

Es könnte sein das man anstatt der Schatten am Panel große weiße Balken sieht. Die kann man aber loswerden indem man einfach die Schattengröße in den Compiz Einstellungen anpasst
Als erstes erstellen wir einfach eine xorg.conf. Xorg macht das automatisch wenn man als root Xorg -configure eingibt. Die erstellte config dann einfach nach /etc/X11/xorg.conf kopieren.
Nun haben wir folgendes Problem: Diese config verwendet als voreingestellte Beschleunigung EXA. Das ist auf meinem Intel Chip mehr als lahm und alles andere als weich und flüssig. Ein anderes Problem ist das in der Xorg Version von OpenSolaris die OffscreenPixmap Funktion per default aktiv ist, das sorgt für teilweise richtig eklige Grafikfehler. Also tragen wir folgendes in die Device Section ein:
Option "AccelMethod" "XAA"
Option "XAANoOffscreenPixmaps" "true"
Ok, jetzt einfach den X-Server neu starten und Compiz unter den visuellen Effekten aktivieren. Und voila: Es wird prollig ;)

Es könnte sein das man anstatt der Schatten am Panel große weiße Balken sieht. Die kann man aber loswerden indem man einfach die Schattengröße in den Compiz Einstellungen anpasst
Mittwoch, 26. November 2008
Uni Münster migriert zu ZFS
Nachdem wir neulich die Ankündigung bekommen haben das unsere Homeverzeichnisse an der Uni umziehen werden und wir in Zukunft einen gewaltigen Performanceboost kriegen, war ich doch mal neugierig was das zu bedeuten hat. Ein kleiner Blick auf unseren Fileserver hat mir folgendes gezeigt:
YAY!!!! Nuff said! :P (btw die Daten sind natürlich verfremdet ;)
pool: pool
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
pool ONLINE 0 0 0
mirror ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
errors: No known data errors
pool: pool2
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
pool2 ONLINE 0 0 0
raidz1 ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
raidz1 ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
errors: No known data errors
NAME SIZE USED AVAIL CAP HEALTH ALTROOT
pool 1.02T 321G 719G 30% ONLINE /
pool2 17.4T 1.59T 15.8T 9% ONLINE /
YAY!!!! Nuff said! :P (btw die Daten sind natürlich verfremdet ;)
Montag, 24. November 2008
OpenSolaris 2008.11 RC2 erschienen
Das ganze gibts auf www.genunix.org zum Runterladen. Bugs bitte auf defect.opensolaris.org melden.
Happy testing :)
Happy testing :)
Montag, 10. November 2008
Papa's got a brandnew pigbag!
Nachdem sich bei mir geradezu ein Rechnermaßensterben zugetragen hat, habe ich mir endlich ein neues Notebook geleistet. Das Lenovo Thinkpad SL500 hochgerüstet auf 4GB RAM: Das perfekte OpenSolaris Notebook. Das einzige was derzeit nicht unterstützt wird ist der Intel 5100 Wlan Chip und für den gibt es bereits Treiber (muss wohl nur noch lernen auch meine Karte zu erkennen, Bugreport ist bereits verschickt und akzeptiert :) ). Ansonsten geht wirklich alles vom Fingerabdruckscanner (naja... als wenns was bringen würde) bis zur Webcam :).

Anmerkung: Ja, den Desktop gibts auch in deutsch. Ich hab meinen allerdings immer englisch, sieht einfach besser aus.
Anmerkung: Ja, den Desktop gibts auch in deutsch. Ich hab meinen allerdings immer englisch, sieht einfach besser aus.
Mittwoch, 5. November 2008
Screencast: ZFS Selbstheilung
Wie ich schon in einem Artikel erwähnt habe, hat ZFS die Möglichkeit Fehler zu erkennen und diese auch selbst zu heilen. Für alle die das mal gerne in Aktion sehen wollen gibt es da einen interessanten Screencast ;). Man brauch auch nicht unbedingt einen Mirror dafür sondern kann einem ZFS sagen das es mehrere Kopien der Daten transparent angelegen soll (mit zfs set copies=n myzfs erzeugt das Filesystem myzfs n Kopien der Daten und kann korrumpierte Daten in Notfall rekonstruieren).
Screencast: ZFS Basics
Passend zu meiner Einführung in ZFS ist jetzt auch ein Screencast erschienen der ein paar der Funktionen von ZFS live zeigt. Immer wieder beeindruckend zu sehen wie schnell ZFS ist.

Dienstag, 4. November 2008
Mythbusting: $FOOFS + LVM = ZFS
Man hört es ja immer wieder wenn man ZFS erwähnt: "Das kann ich doch auch mit LVM machen!" oder "ZFS verletzt ja den ganzen Layergedanken, das gehört getrennt weils ja sonst total Bloatware ist". Damit möchte ich gerne mal in ein paar Punkten aufräumen, vor allem aber auch zeigen das diese Designentscheidung alles andere als willkürlich ist. Dazu werde ich 2 klassische ZFS Beispiele besprechen: Selbstheilung und Intelligentes Prefetching
Sehen wir uns erst einmal an wie ein Mirror auf herkömmliche Art und Weise angelegt ist:

Hier liegt eine klassische Trennung von Filesystem und Volumemanager vor. Das Filesystem hat keinerlei Ahnung das es auf einem Mirror arbeitet der Volumemanager liefert ihm einfach ein virtuelles Device und veranstaltet sein spiegeln unbemerkt vom Filesystem. Auf der anderen Seite kennt der Volumemanager sich aber auch nicht mit dem Filesystem aus, er arbeitet einfach nur mit abstrakten Daten die er wegschreibt und er nicht versteht da er keinerlei Bezug zum Filesystem hat.
ZFS ist hier in 3 Schichten aufgeteilt:
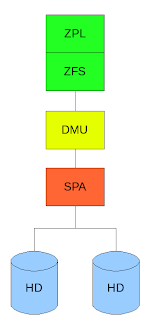
Dem ZFS Posix Layer (ZPL) welcher die normale Posix API zur Verfügung stellt (open,close,read,write etc) darunter liegt direkt das ZFS welches einzelne Transaktionen (ZFS arbeitet NUR mit Transaktionen, dass heißt das das Filesystem nie in einen inkonsistenten Zustand kommt) an die Data Management Unit (DMU) weitergibt welche viele Transaktionen zu einer großen zusammenfasst und der Storage Pool Allocator (SPA) welcher Kenntnis von den Platten (die in unserem Beispiel gespiegelt sind) hat.
Jetzt wollen wir als Beispiel auf einem Spiegel einen fehlerhaften Block haben welcher gelesen wird, sagen wir einfach mal es handelt sich hier um Metadaten welche durch äußere Einwirkungen (Erschütterung, Strahlung, statische Entladung etc) verändert wurden. Der Volumemanager hat hier keine Ahnung ob die Daten korrekt sind und reicht sie ans Filesystem weiter. Im schlimmsten Fall kommt es jetzt zu einer Kernelpanic im weniger schlimmen werden falsche Daten gelesen und die Applikation liefert falsche Ergebnisse oder stürzt ab. Da das Filesystem allerdings keinerlei Ahnung hat das es auf einem Mirror arbeitet kann es selbst wenn es bemerkt das die Daten falsch sind ja nicht wissen das evtl ein Mirror mit richtigen Daten existiert und keine korrekten Daten anfordern (da Volumemanager und Filesystem nun einmal voneinander getrennt sind).
Wie macht ZFS das nun? Als Erstes räumt das Design von ZFS mit dem immer noch verbreiteten Glauben auf das Prüfsummen teuer sind. Bei den heuten Rechnergeschwindigkeiten ist die Berechnung einer solchen Summe zeitlich gesehen zu vernachlässigen. Dies macht sich ZFS zu nutze und sichert JEDEN Block mit einer Prüfsumme (default 256-bit). ZFS erkennt also immer ob ein Block immer noch in dem gleichen Zustand auf der Platte liegt wie es ihn geschrieben hat.
Wir lesen nun den gleichen Block aus dem oberen Beispiel noch einmal. Durch die Prüfsumme erkennen wir das der Block falsch ist und da ZFS selber Kenntnis darüber hat das es auf einem Mirror arbeitet fordert es den gleichen Block von der anderen Platte erneut an. Dieser ist in unserem Beispiel korrekt worauf er an die Applikation weitergereicht wird während der andere fehlerhafte Block verworfen wird und mit dem korrekten von der anderen Platte automatisch überschrieben wird. Die Applikation merkt davon nicht das geringste. (Es ist sogar möglich eine der beiden Platte während eines Lese/Schreibvorgangs mit dd if=/dev/random zu überschreiben ohne das die Applikation fehlerhafte Daten zu sehen kriegt, gleichzeitig wird der Schaden den dd anrichtet transparent geheilt)

Hat man nur eine Festplatte zu Verfügung kann man durch zfs set copies=n filesystem veranlassen das alle Datenblöcke n-fach geschrieben werden. Tritt nun ein Fehler auf wird dieser genauso geheilt wie auf einem Mirror. Man kann so ein extra Filesystem für sehr sensible Daten absichern ohne mehrere Platten zur Verfügung zu haben (z.b. auf Notebooks).
Ein anderes beliebtes Beispiel ist der intelligente Prefetchmechanismus. Nehmen wir folgendes an: Auf einem Filesystem liegt eine Videodatei die gleichzeitig von mehreren Benutzern gelesen wird. Alles in allem sind dies sequentielle Lesezugriffe, da alle diese User jedoch eine andere Stelle der Datei lesen kann man hier mit der herkömmlichen Aufteilung kein sequentielles Pattern erkennen, hier kann also kein Prefetch stattfinden da nicht erkannt wird welcher Block als nächstes gelesen wird. Da ZFS allerdings den Userkontext hat kann es erkennen das es sich hier um mehrere sequentielle Reads handelt und dementsprechend optimieren für normale Filesysteme + Volumemanager bleibt dies aufgrund des mangelnden Kontexts eine zufällige Leseabfolge.
Dies sind nur ein paar Beispiele welche Vorteile das Zusammenlegen von Volumemanager und Filesystem hat, unter anderem kann man damit auch dynamische Stripes haben etc.
ZFS räumt mit Annahmen auf die inzwischen 20 oder 30 Jahre alt sind, es ist komplett neu entwickelt worden mit Blick auf die Computerwelt wie sie heute ist, in der Storagekapazitäten gigantische Ausmaße annehmen und Fehler aufgrund von großen Datendurchsatz sehr leicht auftreten können und möglichst transparent repariert werden sollten. Unter anderem hat ZFS auch die on-disk Struktur stark vereinfacht (Metadaten,inodes welche hier znodes heissen, Daten etc werden gleich behandelt) oder Vorgänge wie formatieren und partitionieren abgeschafft (wer will heute schon 100TB formatieren und auf derartigen Speichermengen noch mit grow und shrink rumhantieren ;) ).
Ergo: Myth BUSTED!
Sehen wir uns erst einmal an wie ein Mirror auf herkömmliche Art und Weise angelegt ist:

Hier liegt eine klassische Trennung von Filesystem und Volumemanager vor. Das Filesystem hat keinerlei Ahnung das es auf einem Mirror arbeitet der Volumemanager liefert ihm einfach ein virtuelles Device und veranstaltet sein spiegeln unbemerkt vom Filesystem. Auf der anderen Seite kennt der Volumemanager sich aber auch nicht mit dem Filesystem aus, er arbeitet einfach nur mit abstrakten Daten die er wegschreibt und er nicht versteht da er keinerlei Bezug zum Filesystem hat.
ZFS ist hier in 3 Schichten aufgeteilt:

Dem ZFS Posix Layer (ZPL) welcher die normale Posix API zur Verfügung stellt (open,close,read,write etc) darunter liegt direkt das ZFS welches einzelne Transaktionen (ZFS arbeitet NUR mit Transaktionen, dass heißt das das Filesystem nie in einen inkonsistenten Zustand kommt) an die Data Management Unit (DMU) weitergibt welche viele Transaktionen zu einer großen zusammenfasst und der Storage Pool Allocator (SPA) welcher Kenntnis von den Platten (die in unserem Beispiel gespiegelt sind) hat.
Jetzt wollen wir als Beispiel auf einem Spiegel einen fehlerhaften Block haben welcher gelesen wird, sagen wir einfach mal es handelt sich hier um Metadaten welche durch äußere Einwirkungen (Erschütterung, Strahlung, statische Entladung etc) verändert wurden. Der Volumemanager hat hier keine Ahnung ob die Daten korrekt sind und reicht sie ans Filesystem weiter. Im schlimmsten Fall kommt es jetzt zu einer Kernelpanic im weniger schlimmen werden falsche Daten gelesen und die Applikation liefert falsche Ergebnisse oder stürzt ab. Da das Filesystem allerdings keinerlei Ahnung hat das es auf einem Mirror arbeitet kann es selbst wenn es bemerkt das die Daten falsch sind ja nicht wissen das evtl ein Mirror mit richtigen Daten existiert und keine korrekten Daten anfordern (da Volumemanager und Filesystem nun einmal voneinander getrennt sind).
Wie macht ZFS das nun? Als Erstes räumt das Design von ZFS mit dem immer noch verbreiteten Glauben auf das Prüfsummen teuer sind. Bei den heuten Rechnergeschwindigkeiten ist die Berechnung einer solchen Summe zeitlich gesehen zu vernachlässigen. Dies macht sich ZFS zu nutze und sichert JEDEN Block mit einer Prüfsumme (default 256-bit). ZFS erkennt also immer ob ein Block immer noch in dem gleichen Zustand auf der Platte liegt wie es ihn geschrieben hat.
Wir lesen nun den gleichen Block aus dem oberen Beispiel noch einmal. Durch die Prüfsumme erkennen wir das der Block falsch ist und da ZFS selber Kenntnis darüber hat das es auf einem Mirror arbeitet fordert es den gleichen Block von der anderen Platte erneut an. Dieser ist in unserem Beispiel korrekt worauf er an die Applikation weitergereicht wird während der andere fehlerhafte Block verworfen wird und mit dem korrekten von der anderen Platte automatisch überschrieben wird. Die Applikation merkt davon nicht das geringste. (Es ist sogar möglich eine der beiden Platte während eines Lese/Schreibvorgangs mit dd if=/dev/random zu überschreiben ohne das die Applikation fehlerhafte Daten zu sehen kriegt, gleichzeitig wird der Schaden den dd anrichtet transparent geheilt)

Hat man nur eine Festplatte zu Verfügung kann man durch zfs set copies=n filesystem veranlassen das alle Datenblöcke n-fach geschrieben werden. Tritt nun ein Fehler auf wird dieser genauso geheilt wie auf einem Mirror. Man kann so ein extra Filesystem für sehr sensible Daten absichern ohne mehrere Platten zur Verfügung zu haben (z.b. auf Notebooks).
Ein anderes beliebtes Beispiel ist der intelligente Prefetchmechanismus. Nehmen wir folgendes an: Auf einem Filesystem liegt eine Videodatei die gleichzeitig von mehreren Benutzern gelesen wird. Alles in allem sind dies sequentielle Lesezugriffe, da alle diese User jedoch eine andere Stelle der Datei lesen kann man hier mit der herkömmlichen Aufteilung kein sequentielles Pattern erkennen, hier kann also kein Prefetch stattfinden da nicht erkannt wird welcher Block als nächstes gelesen wird. Da ZFS allerdings den Userkontext hat kann es erkennen das es sich hier um mehrere sequentielle Reads handelt und dementsprechend optimieren für normale Filesysteme + Volumemanager bleibt dies aufgrund des mangelnden Kontexts eine zufällige Leseabfolge.
Dies sind nur ein paar Beispiele welche Vorteile das Zusammenlegen von Volumemanager und Filesystem hat, unter anderem kann man damit auch dynamische Stripes haben etc.
ZFS räumt mit Annahmen auf die inzwischen 20 oder 30 Jahre alt sind, es ist komplett neu entwickelt worden mit Blick auf die Computerwelt wie sie heute ist, in der Storagekapazitäten gigantische Ausmaße annehmen und Fehler aufgrund von großen Datendurchsatz sehr leicht auftreten können und möglichst transparent repariert werden sollten. Unter anderem hat ZFS auch die on-disk Struktur stark vereinfacht (Metadaten,inodes welche hier znodes heissen, Daten etc werden gleich behandelt) oder Vorgänge wie formatieren und partitionieren abgeschafft (wer will heute schon 100TB formatieren und auf derartigen Speichermengen noch mit grow und shrink rumhantieren ;) ).
Ergo: Myth BUSTED!
Sonntag, 2. November 2008
Die CDDL ist nicht OpenSource?
Anscheinend gibt es immer noch Leute die meinen deratige Parolen schwingen zu müssen (über den Ton den man anderen Personen gegenüber da an den Tag legt will ich hier gar nicht reden). Dabei wiegen Links und andere Beweise wohl anscheinend weniger als "neeeeeeee, wenn ich das sage ist das so". Halten wir die Sache kurz, mit einem Auszug aus der Wikipedia:
Die CDDL wurde am 1. Dezember 2004 der Open Source Initiative zur Abklärung zugesandt und Mitte Januar 2005 für Open-Source-kompatibel befunden. Die CDDL ist auch von der Free Software Foundation (FSF) als freie Lizenz anerkannt.
Und einem Link auf opensource.org.
Langsam nerven diese "heiligen Kriege"...
Die CDDL wurde am 1. Dezember 2004 der Open Source Initiative zur Abklärung zugesandt und Mitte Januar 2005 für Open-Source-kompatibel befunden. Die CDDL ist auch von der Free Software Foundation (FSF) als freie Lizenz anerkannt.
Und einem Link auf opensource.org.
Langsam nerven diese "heiligen Kriege"...
Samstag, 1. November 2008
ZFS: Eine Einführung
Krank sein nervt, aber wenn man im Bett liegt kann man sich mit ein paar Sachen befassen die man sonst eher selten macht. Ich hab die letzten Tage die ich mit Grippe im Bett gelegen hab einfach mal damit verbracht mich in einige ZFS Features einzuarbeiten und mir Gedanken darüber zu machen wie man sie in einem Blog packt. Damit auch die Linuxwelt etwas davon hat hab ich mich auch gleich noch darum gekümmert ZFS unter Ubuntu zum fliegen zu bringen.
Naja lange Rede kurzer Unsinn.
ZFS! Immer wieder hört man das es sich hierbei "nur" um ein Filesystem handelt. Ich will heute mal zeigen das das zwar stimmt, ZFS aber sehr viel mehr ist. Es ist praktisch ein Storage Werkzeugkoffer der fast alles abdeckt was einem in Sachen Storage so über den Weg laufen kann. Das Element mit dem alles anfängt ist der sogenannte zpool. In einem zpool packen wir alles was wir an Storage so nutzen wollen: Festplatte, USB-Sticks, einfach nur Dateien und was weiß ich noch für Devices. Ich werde hier aufgrund eines notorischen Festplattenmangels einfach ganz normale Files nehmen die jeweils 100MB Größe haben.
ZPools
Als erstes werden wir einfach mal die einfachste Sorte von zpools anlegen, nämlich solche die nur aus einem Datenträger bestehen.
Das wars eigentlich schon. Alleine durch die Eingabe von zpool create tank $PWD/disk1 haben wir einen neuen zpool erstellt. Kein formatieren, kein mounten. Das File wurde direkt mit einem ZFS Filesystem auf dem mountpunkt /tank angehängt. Das dauert nur wenige Sekunden.
Was aber machen wenn man mehrere Festplatten hat und deren Platz in einem pool verwenden will?
Wir haben die neue Platte einfach durch add in den zpool eingefügt und wir zpool list zeigt hat sich die Kapazität von tank verdoppelt.
Wir können aber auch zpool mit RAID Fähigkeiten erstellen, dazu gibt es die subkommandos mirror, raidz und raidz2.
Man kann noch sehr viel mehr mit zpools anstellen, aber das reicht fürs erste ;).
Filesysteme
Das erste Filesystem haben wir ja schon mit dem Erstellen des zpools angelegt. Es trägt den Namen tank und ist unter /tank gemountet.
Wir tun jetzt einfach mal so als würden wir eine Art home-Struktur anlegen wollen. Dazu legen wir ein separates home-Filesystem und ein Filesystem für jeden Benutzer an. ZFS Filesysteme sind in etwa vergleichbar mit dem was man unter herkömmlichen Filesystemen als Partitionen bezeichnet, nur das sie sich in ihrer Größe dem Inhalt anpassen. Ein ZFS Filesystem in dem also nichts liegt wird auch praktisch nichts an Plattenplatz belegen.
So wir haben unsere Filesysteme erstellt aber UPS! unsere User sind ja gar nicht an der richtigen Stelle gemountet, eigentlich gehören die ja nach /tank/home. Kein Problem, wir können den Mountpoint im Nachhinein einfach setzen
Das rename ist eigentlich nicht nötig, ich habe es allerdings hier aus Schönheitsgründen mal gemacht ;). Durch das Umsetzen des Mountpoints wird das Filesystem von seinem alten Standort ausgehängt und am neuen Mountpoint eingehängt, alles automatisch.
Wir räumen jetzt einfach mal die anderen Filesysteme weg und arbeiten nur noch mit user1 weiter.
Filesystem Attribute
Jetzt zu ein paar interessanten Attributen die man mit set und get setzen und auslesen kann. Ich werde nur ein paar davon zeigen weil es wirklich eine ganze Menge sind, aber ich halte diese für die praktischsten.
Reservation
Hiermit läßt sich Plattenplatz aus dem zpool reservieren. Dem Filesystem wird also eine bestimmte Menge Storage zugesichert, wie man unten sieht hat tank/home/user1 10MB mehr Speicher zur Verfügung als alle anderen Filesysteme.
Quotas
Was man reservieren kann, kann man aus begrenzen. Mit Quotas lassen sich Filesysteme klein halten.
Compression
Der Name sagt es schon. Filesysteme lassen sich transparent komprimieren. Es gibt unterschiedliche Algorithmen wir nehmen hier gzip als Beispiel.
Hier sollte man daran denken das nur Dateien komprimiert werden die nachträglich im Filesystem erstellt werden. Auch zeigt ls nicht die komprimierte sondern die reale Größe der Datei an.
NFS
Besonders praktisch ist NFS Sharing. Ich werde hier nur die einfachste Form zeigen, aber anstatt on lassen sich die normalen NFS Optionen für das Filesystem angeben. Unter Solaris wird hier alles automatisch eingerichtet und gestartet so das das eingeben einer einzige Zeile reicht um Filesysteme zu sharen (keine Ahnung wie das unter anderem Systemen ist).
Das sind nur ein paar der vielen Attribute die ZFS bietet, alle zu zeigen würden den Rahmen sprengen ;)
Snapshots
Kommen wir zu einem meiner Lieblingsfeatures: Snapshots. Mit Snapshots lassen sich Filesysteme zu einem bestimmten Zeitpunkt einfrieren und auch wieder zurückspielen (und das innerhalb von ein paar Sekunden und ohne das es extra Plattenplatz belegt). Es ist ebenfalls jederzeit möglich in angelegt Snapshots reinzugucken. Wir werden jetzt einfach mal folgendes machen: Wie legen eine Datei mit dem Text "Das ist ein Test" an, danach erstellen wir einen Snapshot und werden die Datei verändern.
Ok wir haben den Zustand unseres Filesystems jetzt unter dem Snapshot mit dem Namen kleinertest gesichert. Nun wollen wir unsere Datei mal kaputtmachen und alles wieder herstellen.
Wie man sieht existiert ein versteckter Ordner .zfs, dieser wird nicht von ls -a angezeigt (Es sei denn man setzt ein bestimmtes Attribut) sondern praktisch on-the-fly erstellt wenn man explizit auf ihn zugreift. Mit zfs rollback spulen wir das Filesystem wieder zu dem Zeitpunkt zurück an dem wir den Snapshot kleinertest erstellt haben (der Snapshot selber existiert weiter). Snapshot sind nicht beschreibbar aber es lassen sich mit zfs clone schreibbare Filesysteme aus einem Snapshot erstellen.
Serialisieren
Ein Filesystem läßt sich in eine einzelne Datei ausgeben die sich dann verschicken läßt und woanders wieder in ein Filesystem umwandeln läßt (sehr praktisch für Backups). Dazu brauchen wir erst einmal einen Snapshot, dieser läßt sich mit zfs send serialisieren und mit zfs receive wieder "entpacken".
Wir haben also nun aus der dump-datei einfach ein neues Userverzeichnis erstellt welches den Zeitpunkt wiederspiegelt an dem wir kleinertest erstellt haben. Snapshots lassen sich auch separat mit zfs list -t snapshot anzeigen
Wie man sieht waren in unserem dump sogar alle Snapshots des Filesystems erhalten (user2 hat ebenfalls einen Snapshot kleinertest)
Import und Export
Filesysteme müssen manchmal mobil sein, z.b. wenn sie auf USB-Sticks liegen. Hierzu kann man zpools einfach exportieren. Exportierte zpools sind ohne das man sie wieder importiert nicht benutzbar (sie werden auch automatisch ausgehängt etc). Steckt man z.b. einen USB-Stick mit einem zpool in das System ein, reicht unter Solaris ein zpool import und alle exportierten Ports werden angezeigt. Ohne Paramter durchsucht dieser Befehl automatisch alle Datenträger nach exportierten zpools im /dev Filesystem.
Da unsere disk Dateien jetzt aber keine echten Devices sind müssen wir den Ort an dem zpool import suchen soll explizit angeben.
Das war ein kleiner aber recht umfangreicher Ausflug in die Welt von ZFS. Und vielen dürfte jetzt klar sein das ZFS mehr ist als nur Volumemanager und Filesystem in einem, es ist ein Storage Verwaltungstools. ZFS ist inzwischen neben Solaris auf FreeBSD, MacOSX und Linux (nur über FUSE) verfügbar. An weiteren Ports wird gearbeitet.
Naja lange Rede kurzer Unsinn.
ZFS! Immer wieder hört man das es sich hierbei "nur" um ein Filesystem handelt. Ich will heute mal zeigen das das zwar stimmt, ZFS aber sehr viel mehr ist. Es ist praktisch ein Storage Werkzeugkoffer der fast alles abdeckt was einem in Sachen Storage so über den Weg laufen kann. Das Element mit dem alles anfängt ist der sogenannte zpool. In einem zpool packen wir alles was wir an Storage so nutzen wollen: Festplatte, USB-Sticks, einfach nur Dateien und was weiß ich noch für Devices. Ich werde hier aufgrund eines notorischen Festplattenmangels einfach ganz normale Files nehmen die jeweils 100MB Größe haben.
ZPools
Als erstes werden wir einfach mal die einfachste Sorte von zpools anlegen, nämlich solche die nur aus einem Datenträger bestehen.
[root@itzkoatl:zfsdemo]> zpool create tank $PWD/disk1
[root@itzkoatl:zfsdemo]> zpool list
NAME SIZE USED AVAIL CAP HEALTH ALTROOT
tank 95.5M 73.5K 95.4M 0% ONLINE -
[root@itzkoatl:zfsdemo]> zpool status tank
pool: tank
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
/export/home/raichoo/zfsdemo/disk1 ONLINE 0 0 0
errors: No known data errors
Das wars eigentlich schon. Alleine durch die Eingabe von zpool create tank $PWD/disk1 haben wir einen neuen zpool erstellt. Kein formatieren, kein mounten. Das File wurde direkt mit einem ZFS Filesystem auf dem mountpunkt /tank angehängt. Das dauert nur wenige Sekunden.
Was aber machen wenn man mehrere Festplatten hat und deren Platz in einem pool verwenden will?
[root@itzkoatl:zfsdemo]> zpool add tank $PWD/disk2
[root@itzkoatl:zfsdemo]> zpool status tank
pool: tank
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
/export/home/raichoo/zfsdemo/disk1 ONLINE 0 0 0
/export/home/raichoo/zfsdemo/disk2 ONLINE 0 0 0
errors: No known data errors
[root@itzkoatl:zfsdemo]> zpool list
NAME SIZE USED AVAIL CAP HEALTH ALTROOT
tank 191M 82.5K 191M 0% ONLINE -
Wir haben die neue Platte einfach durch add in den zpool eingefügt und wir zpool list zeigt hat sich die Kapazität von tank verdoppelt.
Wir können aber auch zpool mit RAID Fähigkeiten erstellen, dazu gibt es die subkommandos mirror, raidz und raidz2.
[root@itzkoatl:zfsdemo]> zpool create tank mirror $PWD/disk1 $PWD/disk2
[root@itzkoatl:zfsdemo]> zpool status tank
pool: tank
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
mirror ONLINE 0 0 0
/export/home/raichoo/zfsdemo/disk1 ONLINE 0 0 0
/export/home/raichoo/zfsdemo/disk2 ONLINE 0 0 0
errors: No known data errors
...
[root@itzkoatl:zfsdemo]> zpool create tank raidz2 $PWD/disk1 $PWD/disk2 $PWD/disk3 $PWD/disk4
[root@itzkoatl:zfsdemo]> zpool status tank
pool: tank
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
raidz2 ONLINE 0 0 0
/export/home/raichoo/zfsdemo/disk1 ONLINE 0 0 0
/export/home/raichoo/zfsdemo/disk2 ONLINE 0 0 0
/export/home/raichoo/zfsdemo/disk3 ONLINE 0 0 0
/export/home/raichoo/zfsdemo/disk4 ONLINE 0 0 0
errors: No known data errors
Man kann noch sehr viel mehr mit zpools anstellen, aber das reicht fürs erste ;).
Filesysteme
Das erste Filesystem haben wir ja schon mit dem Erstellen des zpools angelegt. Es trägt den Namen tank und ist unter /tank gemountet.
[root@itzkoatl:zfsdemo]> zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 98.6K 158M 26.9K /tank
Wir tun jetzt einfach mal so als würden wir eine Art home-Struktur anlegen wollen. Dazu legen wir ein separates home-Filesystem und ein Filesystem für jeden Benutzer an. ZFS Filesysteme sind in etwa vergleichbar mit dem was man unter herkömmlichen Filesystemen als Partitionen bezeichnet, nur das sie sich in ihrer Größe dem Inhalt anpassen. Ein ZFS Filesystem in dem also nichts liegt wird auch praktisch nichts an Plattenplatz belegen.
[root@itzkoatl:zfsdemo]> zfs create tank/home
[root@itzkoatl:zfsdemo]> zfs create tank/user1
[root@itzkoatl:zfsdemo]> zfs create tank/user2
[root@itzkoatl:zfsdemo]> zfs create tank/user3
[root@itzkoatl:zfsdemo]> zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 247K 158M 34.4K /tank
tank/home 26.9K 158M 26.9K /tank/home
tank/user1 26.9K 158M 26.9K /tank/user1
tank/user2 26.9K 158M 26.9K /tank/user2
tank/user3 26.9K 158M 26.9K /tank/user3
So wir haben unsere Filesysteme erstellt aber UPS! unsere User sind ja gar nicht an der richtigen Stelle gemountet, eigentlich gehören die ja nach /tank/home. Kein Problem, wir können den Mountpoint im Nachhinein einfach setzen
[root@itzkoatl:tank]> zfs set mountpoint=/tank/home/user1 tank/user1
[root@itzkoatl:tank]> zfs rename tank/user1 tank/home/user1
[root@itzkoatl:tank]> zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 258K 158M 32.9K /tank
tank/home 55.3K 158M 28.4K /tank/home
tank/home/user1 26.9K 158M 26.9K /tank/home/user1
tank/user2 26.9K 158M 26.9K /tank/user2
tank/user3 26.9K 158M 26.9K /tank/user3
Das rename ist eigentlich nicht nötig, ich habe es allerdings hier aus Schönheitsgründen mal gemacht ;). Durch das Umsetzen des Mountpoints wird das Filesystem von seinem alten Standort ausgehängt und am neuen Mountpoint eingehängt, alles automatisch.
Wir räumen jetzt einfach mal die anderen Filesysteme weg und arbeiten nur noch mit user1 weiter.
[root@itzkoatl:tank]> zfs destroy tank/user2
[root@itzkoatl:tank]> zfs destroy tank/user3
Filesystem Attribute
Jetzt zu ein paar interessanten Attributen die man mit set und get setzen und auslesen kann. Ich werde nur ein paar davon zeigen weil es wirklich eine ganze Menge sind, aber ich halte diese für die praktischsten.
Reservation
Hiermit läßt sich Plattenplatz aus dem zpool reservieren. Dem Filesystem wird also eine bestimmte Menge Storage zugesichert, wie man unten sieht hat tank/home/user1 10MB mehr Speicher zur Verfügung als alle anderen Filesysteme.
[root@itzkoatl:tank]> zfs set reservation=10m tank/home/user1
[root@itzkoatl:tank]> zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 10.2M 148M 28.4K /tank
tank/home 10.0M 148M 28.4K /tank/home
tank/home/user1 26.9K 158M 26.9K /tank/home/user1
Quotas
Was man reservieren kann, kann man aus begrenzen. Mit Quotas lassen sich Filesysteme klein halten.
[root@itzkoatl:tank]> zfs set quota=10m tank/home/user1
[root@itzkoatl:tank]> zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 10.2M 148M 28.4K /tank
tank/home 10.0M 148M 28.4K /tank/home
tank/home/user1 26.9K 9.97M 26.9K /tank/home/user1
Compression
Der Name sagt es schon. Filesysteme lassen sich transparent komprimieren. Es gibt unterschiedliche Algorithmen wir nehmen hier gzip als Beispiel.
[root@itzkoatl:tank]> zfs set compression=gzip tank/home/user1
[root@itzkoatl:tank]> zfs get compression tank/home/user1
NAME PROPERTY VALUE SOURCE
tank/home/user1 compression gzip local
Hier sollte man daran denken das nur Dateien komprimiert werden die nachträglich im Filesystem erstellt werden. Auch zeigt ls nicht die komprimierte sondern die reale Größe der Datei an.
NFS
Besonders praktisch ist NFS Sharing. Ich werde hier nur die einfachste Form zeigen, aber anstatt on lassen sich die normalen NFS Optionen für das Filesystem angeben. Unter Solaris wird hier alles automatisch eingerichtet und gestartet so das das eingeben einer einzige Zeile reicht um Filesysteme zu sharen (keine Ahnung wie das unter anderem Systemen ist).
[root@itzkoatl:tank]> zfs set sharenfs=on tank/home/user1
Das sind nur ein paar der vielen Attribute die ZFS bietet, alle zu zeigen würden den Rahmen sprengen ;)
Snapshots
Kommen wir zu einem meiner Lieblingsfeatures: Snapshots. Mit Snapshots lassen sich Filesysteme zu einem bestimmten Zeitpunkt einfrieren und auch wieder zurückspielen (und das innerhalb von ein paar Sekunden und ohne das es extra Plattenplatz belegt). Es ist ebenfalls jederzeit möglich in angelegt Snapshots reinzugucken. Wir werden jetzt einfach mal folgendes machen: Wie legen eine Datei mit dem Text "Das ist ein Test" an, danach erstellen wir einen Snapshot und werden die Datei verändern.
[root@itzkoatl:user1]> echo "Das ist ein Test" > text
[root@itzkoatl:user1]> ls
text
[root@itzkoatl:user1]> cat text
Das ist ein Test
[root@itzkoatl:user1]> zfs snapshot tank/home/user1@kleinertest
Ok wir haben den Zustand unseres Filesystems jetzt unter dem Snapshot mit dem Namen kleinertest gesichert. Nun wollen wir unsere Datei mal kaputtmachen und alles wieder herstellen.
[root@itzkoatl:user1]> echo "Ich mach alles kaputt!" >| text
[root@itzkoatl:user1]> cat text
Ich mach alles kaputt!
[root@itzkoatl:user1]> cat .zfs/snapshot/kleinertest/text
Das ist ein Test
[root@itzkoatl:user1]> zfs rollback tank/home/user1@kleinertest
[root@itzkoatl:user1]> cat text
Das ist ein Test
Wie man sieht existiert ein versteckter Ordner .zfs, dieser wird nicht von ls -a angezeigt (Es sei denn man setzt ein bestimmtes Attribut) sondern praktisch on-the-fly erstellt wenn man explizit auf ihn zugreift. Mit zfs rollback spulen wir das Filesystem wieder zu dem Zeitpunkt zurück an dem wir den Snapshot kleinertest erstellt haben (der Snapshot selber existiert weiter). Snapshot sind nicht beschreibbar aber es lassen sich mit zfs clone schreibbare Filesysteme aus einem Snapshot erstellen.
Serialisieren
Ein Filesystem läßt sich in eine einzelne Datei ausgeben die sich dann verschicken läßt und woanders wieder in ein Filesystem umwandeln läßt (sehr praktisch für Backups). Dazu brauchen wir erst einmal einen Snapshot, dieser läßt sich mit zfs send serialisieren und mit zfs receive wieder "entpacken".
[root@itzkoatl:user1]> zfs send tank/home/user1@kleinertest > /tank/dump
[root@itzkoatl:user1]> ls -l /tank/dump
-rw-r--r-- 1 root root 15680 Nov 1 17:29 /tank/dump
[root@itzkoatl:user1]> zfs receive tank/home/user2 < /tank/dump
[root@itzkoatl:user1]> cat /tank/home/user2/text
Das ist ein Test
[root@itzkoatl:user1]> zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 10.2M 148M 45.6K /tank
tank/home 10.1M 148M 31.4K /tank/home
tank/home/user1 29.1K 9.97M 29.1K /tank/home/user1
tank/home/user2 27.6K 148M 27.6K /tank/home/user2
Wir haben also nun aus der dump-datei einfach ein neues Userverzeichnis erstellt welches den Zeitpunkt wiederspiegelt an dem wir kleinertest erstellt haben. Snapshots lassen sich auch separat mit zfs list -t snapshot anzeigen
[root@itzkoatl:user1]> zfs list -t snapshot
NAME USED AVAIL REFER MOUNTPOINT
tank/home/user1@kleinertest 0 - 29.1K -
tank/home/user2@kleinertest 0 - 27.6K -
Wie man sieht waren in unserem dump sogar alle Snapshots des Filesystems erhalten (user2 hat ebenfalls einen Snapshot kleinertest)
Import und Export
Filesysteme müssen manchmal mobil sein, z.b. wenn sie auf USB-Sticks liegen. Hierzu kann man zpools einfach exportieren. Exportierte zpools sind ohne das man sie wieder importiert nicht benutzbar (sie werden auch automatisch ausgehängt etc). Steckt man z.b. einen USB-Stick mit einem zpool in das System ein, reicht unter Solaris ein zpool import und alle exportierten Ports werden angezeigt. Ohne Paramter durchsucht dieser Befehl automatisch alle Datenträger nach exportierten zpools im /dev Filesystem.
Da unsere disk Dateien jetzt aber keine echten Devices sind müssen wir den Ort an dem zpool import suchen soll explizit angeben.
[root@itzkoatl:~]> zpool export tank
[root@itzkoatl:~]> zpool import -d ./zfsdemo
pool: tank
id: 14691414290482700440
state: ONLINE
action: The pool can be imported using its name or numeric identifier.
config:
tank ONLINE
raidz2 ONLINE
/export/home/raichoo/zfsdemo/disk1 ONLINE
/export/home/raichoo/zfsdemo/disk2 ONLINE
/export/home/raichoo/zfsdemo/disk3 ONLINE
/export/home/raichoo/zfsdemo/disk4 ONLINE
[root@itzkoatl:~]> zpool import -d ./zfsdemo tank
Das war ein kleiner aber recht umfangreicher Ausflug in die Welt von ZFS. Und vielen dürfte jetzt klar sein das ZFS mehr ist als nur Volumemanager und Filesystem in einem, es ist ein Storage Verwaltungstools. ZFS ist inzwischen neben Solaris auf FreeBSD, MacOSX und Linux (nur über FUSE) verfügbar. An weiteren Ports wird gearbeitet.
ZFS unter Ubuntu Intrepid Ibex
ZFS und Linux ist ja leider ein Thema für sich, aber mit ein paar Handgriffen kann man es sich zumindest so zurechtbiegen das es unter FUSE im Userspace rennt. Auch wenn das nicht gerade die performanteste Lösung auf Erden ist kann man so wenigstens seine zpools unter Linux benutzen.
Um die aktuelle Version 0.5.0 zu kompilieren muss man lediglich die folgenden Pakete nachinstallieren:
build-essential libfuse-dev libaio-dev zlib1g-dev scons
Die aktuelle "ZFS on FUSE" Version findet man hier. Übersetzen und installieren läßt sich das ganze nachdem wir die oben genannten Pakete installiert haben:
Mit sudo zfs-fuse starten wir den Userspace Prozess der ZFS verwaltet.
Leider schmeißt der Code sehr viele Warnings und es ist gleichzeitig das -Werror Flag gesetzt welches ein kompilieren in diesem Fall unmöglich macht. Also entfernen wir dieses Flag aus der src/SConstruct aus dem CFLAGS Eintrage. Das ganze sieht dann so aus:
Ich weiß das ist unschön und gehört eigentlich verboten... vielleicht kennt jemand einen besseren Weg, ich würde mich sehr über Tipps freuen.

Ich plane im Moment eine kleine ZFS Einführung an der jetzt hoffentlich auch die Linuxuser ihren Spaß haben werden.
Um die aktuelle Version 0.5.0 zu kompilieren muss man lediglich die folgenden Pakete nachinstallieren:
build-essential libfuse-dev libaio-dev zlib1g-dev scons
Die aktuelle "ZFS on FUSE" Version findet man hier. Übersetzen und installieren läßt sich das ganze nachdem wir die oben genannten Pakete installiert haben:
raichoo@tensaiga:Projects$ tar xfvj zfs-fuse-0.5.0.tar.bz2
...
raichoo@tensaiga:Projects$ cd zfs-fuse-0.5.0/src
raichoo@tensaiga:Projects$ scons
...
raichoo@tensaiga:Projects$ sudo scons install
Mit sudo zfs-fuse starten wir den Userspace Prozess der ZFS verwaltet.
Leider schmeißt der Code sehr viele Warnings und es ist gleichzeitig das -Werror Flag gesetzt welches ein kompilieren in diesem Fall unmöglich macht. Also entfernen wir dieses Flag aus der src/SConstruct aus dem CFLAGS Eintrage. Das ganze sieht dann so aus:
env['CCFLAGS'] = Split('-pipe -Wall -std=c99 -Wno-switch
-Wno-unused -Wno-missing-braces -Wno-parentheses
-Wno-uninitialized -fno-strict-aliasing -D_GNU_SOURCE
-D_FILE_OFFSET_BITS=64 -D_REENTRANT
-DTEXT_DOMAIN=\\"zfs-fuse\\" -DLINUX_AIO')
Ich weiß das ist unschön und gehört eigentlich verboten... vielleicht kennt jemand einen besseren Weg, ich würde mich sehr über Tipps freuen.

Ich plane im Moment eine kleine ZFS Einführung an der jetzt hoffentlich auch die Linuxuser ihren Spaß haben werden.
Sonntag, 26. Oktober 2008
Wie ZFS das Booten verändert
ZFS ändert nicht nur die Art und Weise wie wir mit Filesystemen umgehen (kein Partitionieren und Formatieren mehr etc.) sondern auch wie wir booten. Wie das alles technisch funktioniert und welche Möglichkeiten das eröffnet hat Lori Alt in einem sehr sehenswerten Vortrag erläutert. Die Beispiele sind auf Solaris 10 bezogen. Unter der OpenSolaris Distro verwenden wir nicht die LU Tools sondern BEadm.
Ein kleiner Preview auf 2008.11
Gman hat hier auf ein Video Review zum Thema OpenSolaris geantwortet und ein paar interessante Ankündigungen für 2008.11 gemacht. Besonders interessant finde ich den automatisierten Installer und den "Distribution Creator" mit dem man sich seine eigene Distro maßschneidern kann (Mit KDE4 Paketen könnte man sich dann eine KDE OpenSolaris Distro selberbacken ^^). Es bleibt also wie immer spannend.
Samstag, 25. Oktober 2008
Constantin Gonzalez zeigt wie's geht
Solaris hat ja immer den Ruf ziemlich benutzerunfreundlich gewesen zu sein, mit der OpenSolaris Distribution von Sun soll sich das jetzt ändern mit der derzeitigen Version 2008.05 hat sich zwar schon vieles verbessert aber sicherlich bleibt noch einiges zu tun (2008.11 welches gegen Ende November erscheint wird da allerdings sehr viel neues dazubringen ;).
Für alle die einfach mal sehen wollen wie "schwer" es ist OpenSolaris zu installieren hier einfach mal ein kleiner Video Podcast von SunVision.tv
Besonders praktisch ist das Device Utility welches gleich auf dem Desktop liegt und gleich anzeigt welche Geräte unterstützt werden (hat mir bei meiner Entscheidung welches Notebook ich kaufen will seeeeeeehr geholfen ^^). Sollte mit der aktuellen LiveCD einiges nicht klappen kann man auch einfach auf den aktuellen Build auf Genunix.org zurückgreifen (im Moment ist Build 99 aktuell). Diese Builds erscheinen meistens alle 2 Wochen und erhalten jedesmal jede Menge Bugfixes, neue Features und auch neue Treiber und lassen sich wie die normale OpenSolaris CD als LiveCD nutzen.
Für alle die einfach mal sehen wollen wie "schwer" es ist OpenSolaris zu installieren hier einfach mal ein kleiner Video Podcast von SunVision.tv
Besonders praktisch ist das Device Utility welches gleich auf dem Desktop liegt und gleich anzeigt welche Geräte unterstützt werden (hat mir bei meiner Entscheidung welches Notebook ich kaufen will seeeeeeehr geholfen ^^). Sollte mit der aktuellen LiveCD einiges nicht klappen kann man auch einfach auf den aktuellen Build auf Genunix.org zurückgreifen (im Moment ist Build 99 aktuell). Diese Builds erscheinen meistens alle 2 Wochen und erhalten jedesmal jede Menge Bugfixes, neue Features und auch neue Treiber und lassen sich wie die normale OpenSolaris CD als LiveCD nutzen.
OpenSolaris Usergroup Münster/Bielefeld/Osnabrück
Ich nehme hiermit einfach mal die Freiheit eine OpenSolaris Usergroup für den Bereich Münster, Bielefeld und Osnabrück auszurufen. Frei nach Jim's 10 Punkte Plan für eine erfolgreiche Usergroup geht es erst einmal darum Interessenten zu finden und einen kleinen Stammtisch zu organisieren. Als Anlaufpunkt kann man sich gerne bei mir melden oder ihr schaut einfach in unserem Community Channel #opensolaris-de auf Freenode vorbei. Jeder ist willkommen, egal ob Profi oder einfach nur Neugieriger. Alles ist noch offen für neue Ideen und Anregungen ;)
Freitag, 24. Oktober 2008
"Less know Solaris Features" Handbuch zum Download
Für alle die sowas wie das FreeBSD Handbuch für Solaris suchen gibt es jetzt etwas interessantes auf http://www.c0t0d0s0.org. Auch sonst ein durchaus lesenswerter Blog ;)
Freitag, 17. Oktober 2008
ZFS für Linux kriegt ein Upgrade
Totgesagte leben länger heißt es ja so schön. So ist in dem ganzen Rummel um das Datenbank-Filesystem Btrfs und die neue ext Version wohl untergegangen das es schon im letzten Monat ein Upgrade für ZFS on Fuse. Die neue Version unterstützt unter anderem ZFS Pools der Version 13 und beseitigt kritische Bugs. Das eröffnet die Möglichkeit ZFS Wechseldatenträger jetzt auf Mac OS X, FreeBSD, Linux und natürlich Solaris zu nutzen (wenn Windows jetzt noch ZFS kriegen würde könnte man endlich auf FAT verzichten... *träum*). Weitere Open Source Betriebssysteme wie NetBSD und DragonflyBSD arbeiten ebenfalls an einer Portierung. Natives ZFS unter Linux ist derzeit nicht möglich da die GPL das mischen mit Open Source Code der nicht unter GPL steht verbietet (bei Nvidia-Treibern scheint es zu gehen... ein Schelm wer Böses denkt ;) ).
Mich persönlich würde interessieren wie hoch der Performanceverlust ist wenn man ein derartig komplexes Filesystem im Userspace laufen läßt. Falls Linux-user mit ZFS Erfahrung das lesen würde mich ein Feedback interessieren.
Mich persönlich würde interessieren wie hoch der Performanceverlust ist wenn man ein derartig komplexes Filesystem im Userspace laufen läßt. Falls Linux-user mit ZFS Erfahrung das lesen würde mich ein Feedback interessieren.
Spaß mit Solaris-Zones
Zones werden immer wieder als eins von den Killer Features von Solaris genannt. Es handelt sich hierbei um eine Art leichtgewichtige Virtualisierung ähnlich den FreeBSD Jails, nur sehr viel mächtiger. Unter anderem ist es auch möglich sogenannte "branded zones", welche z.B. Linux virtualisieren, anzulegen.
Ich werde heute erst einmal zeigen wie man eine Zone vom Typ ipkg anlegt, dies sind einfache Instanzen von Solaris. Sie laufen völlig abgeschottet vom Rest das Systems. In ihnen lassen sich separate Services fahren und man kann ihnen unter anderem eingeschränkte Ressourcen (z.b. eine einzelne CPU von einem SMP System) zuweisen.
Ein Beispiel: In einer Zone läuft ein Webserver auf den ein Angriff gelingt. Der Angreifer hat sich jetzt zwar Zugriff auf die Zone verschafft, kann aber nicht auf andere Services in anderen Zones zugreifen oder auf das Hauptsystem welches von der Zone aus nicht sichtbar ist. Eine DoS Attacke die z.b. versucht alle Ressourcen des Systems aufzubrauchen schlägt fehl da diese beschränkt sind.
Um Zones anzulegen und zu verwalten greift man auf die Tools zonecfg und zoneadm zurück.
Als erstes listen wir einfach mal alle Zonen auf die wir haben:
global steht für unser Hauptsystem. Die Option -c zeigt uns Zonen an die im Status configured sind, dazu aber später.
Nun wollen wir unser System fit für Zones machen. Ich lege dazu einfach ein zusätzliches ZFS Filesystem im Ordner /export an. Dies geschieht einfach durch den Befehl zfs create rpool/export/zones. (Zones brauchen anscheinend ein separates Filesystem auf dem sie angelegt werden).
Originell wie wir sind legen wir jetzt eine Zone mit dem Namen "test" an:
Mit create lege ich die Zone an, nun muss ich lediglich einen Pfad angeben in dem die Zone beherbergt werden soll (dafür haben wir ja gerade unser ZFS Filesystem errpool/export/zones erstellt). Mit verify überprüfen wir ob auch alles ok ist und mit commit legen wir dann die Konfiguration an (Für alle die es interessiert: die Konfiguration wird in /etc/zones/test.xml gespeichert).
Unsere Zone befindet sich nun im Status configured, das bedeutet das wir jetzt ein System in die Zone installieren können. Nachdem wir das System erfolgreich in die Zone installiert haben läßt sie sich wie ein separater Rechner booten und wir können uns mit zlogin einloggen.
Jetzt werden wir durch eine Installationsroutine geführt (Zum Fortfahren einfach ESC-2 drücken). Danach läuft eine virtualisierte Instanz von Solaris auf unserem System. Übrigens beim erstellen einer neuen Zone wird pkg eventuell einige Pakete herunterladen, dies geschieht aber nur einmal und zukünftige Zones werden sich die Pakete einfach aus dem Package-cache ziehen.
Jetzt wollen wir als kleines i-Tüpfelchen noch eine virtuelle Netzwerkkarte hinzufügen und unserer Zone eine eigene IP geben ;)
Dazu machen wir im Hostsystem folgendes:
Wie man sieht sorgen Zones sogar für Abhilfe wenn man vergessen hat die Subnetzmaske einzugeben ;). (Für alle die mit rtls0 nichts anfangen können: das ist der Name der Netzwerkkarte, in diesem Fall eine Realtek)
Unsere Zone ist jetzt im gesamten Netzwerk unter 192.168.1.111 erreichbar ;)
Wozu kann man Zones denn jetzt alles missbrauchen? Mit "branded zones" kann man z.B. Linux Applikationen ausführen (dazu eventuell später mal), oder man kann einfach eine abgeschottete Zone für Entwicklung einrichten, warum nicht einfach jedem seiner Freunde eine eigene Zone auf eurem Solaris Server geben? ;)
Ich werde heute erst einmal zeigen wie man eine Zone vom Typ ipkg anlegt, dies sind einfache Instanzen von Solaris. Sie laufen völlig abgeschottet vom Rest das Systems. In ihnen lassen sich separate Services fahren und man kann ihnen unter anderem eingeschränkte Ressourcen (z.b. eine einzelne CPU von einem SMP System) zuweisen.
Ein Beispiel: In einer Zone läuft ein Webserver auf den ein Angriff gelingt. Der Angreifer hat sich jetzt zwar Zugriff auf die Zone verschafft, kann aber nicht auf andere Services in anderen Zones zugreifen oder auf das Hauptsystem welches von der Zone aus nicht sichtbar ist. Eine DoS Attacke die z.b. versucht alle Ressourcen des Systems aufzubrauchen schlägt fehl da diese beschränkt sind.
Um Zones anzulegen und zu verwalten greift man auf die Tools zonecfg und zoneadm zurück.
Als erstes listen wir einfach mal alle Zonen auf die wir haben:
[root@itzkoatl:zones]> zoneadm list -cv
ID NAME STATUS PATH BRAND IP
0 global running / native shared
global steht für unser Hauptsystem. Die Option -c zeigt uns Zonen an die im Status configured sind, dazu aber später.
Nun wollen wir unser System fit für Zones machen. Ich lege dazu einfach ein zusätzliches ZFS Filesystem im Ordner /export an. Dies geschieht einfach durch den Befehl zfs create rpool/export/zones. (Zones brauchen anscheinend ein separates Filesystem auf dem sie angelegt werden).
Originell wie wir sind legen wir jetzt eine Zone mit dem Namen "test" an:
[root@itzkoatl:~]> zonecfg -z test
test: No such zone configured
Use 'create' to begin configuring a new zone.
zonecfg:test> create
zonecfg:test> set zonepath=/export/zones/test
zonecfg:test> verify
zonecfg:test> commit
zonecfg:test> exit
[root@itzkoatl:~]> zoneadm list -cv
ID NAME STATUS PATH BRAND IP
0 global running / native shared
- test configured /export/zones/test ipkg shared
Mit create lege ich die Zone an, nun muss ich lediglich einen Pfad angeben in dem die Zone beherbergt werden soll (dafür haben wir ja gerade unser ZFS Filesystem errpool/export/zones erstellt). Mit verify überprüfen wir ob auch alles ok ist und mit commit legen wir dann die Konfiguration an (Für alle die es interessiert: die Konfiguration wird in /etc/zones/test.xml gespeichert).
Unsere Zone befindet sich nun im Status configured, das bedeutet das wir jetzt ein System in die Zone installieren können. Nachdem wir das System erfolgreich in die Zone installiert haben läßt sie sich wie ein separater Rechner booten und wir können uns mit zlogin einloggen.
[root@itzkoatl:~]> zoneadm -z test install
A ZFS file system has been created for this zone.
Authority: Using http://pkg.opensolaris.org:80/.
Image: Preparing at /export/zones/test/root ... done.
Cache: Using /var/pkg/download.
Installing: (output follows)
DOWNLOAD PKGS FILES XFER (MB)
Completed 52/52 7842/7842 75.32/75.32
PHASE ACTIONS
Install Phase 12903/12903
PHASE ITEMS
Reading Existing Index 9/9
Indexing Packages 52/52
Note: Man pages can be obtained by installing SUNWman
Postinstall: Copying SMF seed repository ... done.
Postinstall: Working around http://defect.opensolaris.org/bz/show_bug.cgi?id=741
Done: Installation completed in 268.109 seconds.
Next Steps: Boot the zone, then log into the zone console
(zlogin -C) to complete the configuration process
[root@itzkoatl:~]> zoneadm -z test boot
[root@itzkoatl:~]> zlogin -C test
[Connected to zone 'test' console]
(hier hab ich noch mal ENTER drücken müssen)
You did not enter a selection.
What type of terminal are you using?
1) ANSI Standard CRT
2) DEC VT100
3) PC Console
4) Sun Command Tool
5) Sun Workstation
6) X Terminal Emulator (xterms)
7) Other
Type the number of your choice and press Return:
...
test console login: root
Password:
Oct 17 14:53:45 test login: ROOT LOGIN /dev/console
Sun Microsystems Inc. SunOS 5.11 snv_99 November 2008
root@test:~#
Jetzt werden wir durch eine Installationsroutine geführt (Zum Fortfahren einfach ESC-2 drücken). Danach läuft eine virtualisierte Instanz von Solaris auf unserem System. Übrigens beim erstellen einer neuen Zone wird pkg eventuell einige Pakete herunterladen, dies geschieht aber nur einmal und zukünftige Zones werden sich die Pakete einfach aus dem Package-cache ziehen.
Jetzt wollen wir als kleines i-Tüpfelchen noch eine virtuelle Netzwerkkarte hinzufügen und unserer Zone eine eigene IP geben ;)
Dazu machen wir im Hostsystem folgendes:
[root@itzkoatl:export]> zonecfg -z test
zonecfg:test> add net
zonecfg:test:net> set physical=rtls0
zonecfg:test:net> set address=192.168.1.111
zonecfg:test:net> end
zonecfg:test> verify
zonecfg:test> commit
zonecfg:test> exit
[root@itzkoatl:export]> zoneadm -z test reboot
zone 'test': WARNING: rtls0:1: no matching subnet found in netmasks(4) for 192.168.1.111; using default of 255.255.255.0.
Wie man sieht sorgen Zones sogar für Abhilfe wenn man vergessen hat die Subnetzmaske einzugeben ;). (Für alle die mit rtls0 nichts anfangen können: das ist der Name der Netzwerkkarte, in diesem Fall eine Realtek)
Unsere Zone ist jetzt im gesamten Netzwerk unter 192.168.1.111 erreichbar ;)
Wozu kann man Zones denn jetzt alles missbrauchen? Mit "branded zones" kann man z.B. Linux Applikationen ausführen (dazu eventuell später mal), oder man kann einfach eine abgeschottete Zone für Entwicklung einrichten, warum nicht einfach jedem seiner Freunde eine eigene Zone auf eurem Solaris Server geben? ;)
Montag, 13. Oktober 2008
OpenSolaris 2008.11 ermöglicht Zeitreisen
Jeder der sich schon mal einen Mac angesehen hat kennt vermutlich Time Machine: das mitgelieferte Backup Tool von Apple. Ein ziemlich praktisches Feature, das in ähnlicher Form für den nächsten Release von OpenSolaris im November angekündigt ist. Das Ganze wird mit Hilfe von ZFS realisiert (schon mal ein großer Vorteil gegenüber Mac OS X welches IIRC rsync nutzt) und in Nautilus eingebettet, ein SMF Service sorgt im Hintergrund für regelmäßige Snapshots die sich dann per "Time Slider" durchforsten lassen.
Ob es irgendwann auch ein funky Compiz Plugin geben wird das wie auf dem Mac einen Flug durch einen Zeittunnel realisiert bleibt wohl abzuwarten ^^.
Mehr Informationen finden sich hier.
Update: Mir wurde gerade gesagt das Mac OS X doch kein rysnc verwendet sondern "die FSEvent API" (was immer das ist ^^). Danke Okona ;)
Ob es irgendwann auch ein funky Compiz Plugin geben wird das wie auf dem Mac einen Flug durch einen Zeittunnel realisiert bleibt wohl abzuwarten ^^.
Mehr Informationen finden sich hier.
Update: Mir wurde gerade gesagt das Mac OS X doch kein rysnc verwendet sondern "die FSEvent API" (was immer das ist ^^). Danke Okona ;)
OpenSolaris und Multimedia
Multimedia ist ja unter OpenSolaris anfangs eine ziemliche leidige Sache gewesen: kein mplayer, xine.... irgendwie konnte man nur sehr beschränkt out-of-the-box Multimediadateien abspielen. Im Paketkatalog fand man auch nicht wirklich Abhilfe. Inzwischen haben sich aber ein paar fleißige Japaner daran gemacht bewegte Bilder auch noch in die OpenSolaris Welt zu bringen. Life with Solaris heißt das ganze und bietet mit ein paar Handgriffen alles das was man sich so wünscht. Einfach folgendes ausführen (mit root-Rechten versteht sich):
Schon hat man Zugriff auf die Pakete von Life with Solaris.
Weitergehende Informationen finden sich hier.
# pkg set-authority -O http://pkg.lifewithsolaris.jp:10000/ lifewithsolaris.jp
# pkg refresh --full
Schon hat man Zugriff auf die Pakete von Life with Solaris.
Weitergehende Informationen finden sich hier.
Donnerstag, 9. Oktober 2008
BEadm: Ich bin nicht eins, ich bin viele
Ein Feature von OpenSolaris welches ich besonders liebe ist beadm, die Boot Environment Verwaltung. Hier mit kann man mehrere Instanzen des Systems auf seiner Platte installiert haben und benutzten. "Mooooment mal? Frisst das nicht unheimlich viel Plattenplatz wenn ich 3, 4 oder sogar mehr Versionen von OpenSolaris auf meiner Platte habe?" Genau das ist ja das schöne, NEIN! Unterschiedliche Bootumgebungen belegen nur Plattenplatz für die Unterschiede zwischen den Systemen, habe ich also nur kleine Änderungen vorgenommen belegt das System auch so gut wie keinen Plattenplatz. "Wie viele unterschiedliche Instanzen kann ich denn machen?" So viele wie man will! Ich selber habe immer noch eine Kopie des letzten Releases auf meiner Platte, auf meinem Notebook sogar noch eine Version von der frischen Installation welche ich im Notfall immer als eine Art "Rettungsversion" nutzen kann. Auf meinem Desktop sieht das ganze so aus:
Das sind also 2 Bootumgebungen. Wie man sieht belegt opensolaris_snv97 nur 55,57 MB an Plattenplatz obwohl es den KOMPLETTEN Zustand meines Systems (Anmerkung: Nur das System, mein Homefilesystem bleibt davon unberührt und kann auf jeder Instanz genutzt werden) vor dem letzten Upgrade repräsentiert. Diese Umgebung kann ich jetzt nach belieben vervielfältigen und damit weiterarbeiten oder einfach löschen wenn ich sie nicht mehr brauche. Was allerdings am wichtigsten ist: ich kann auf sie jederzeit zugreifen. Dies funktioniert fast genauso wie das händische mounten eines Datenträgers:
Man beachte das es hier unmount und nicht umount heißt ;)
Das erstellen und zerstören einer Bootumgebung ist ebenso einfach:
Voila, das wars. Der Vorgang dauert satte 3 Sekunden und wie man sieht belegt donnerlutzi nur 80.5 KB an Plattenplatz. "Hmm... brauch ich da nicht noch einen Eintrag im Bootmanager damit ich in das System booten kann?" Nö, das macht beadm schon von ganz alleine ;)
Will ich donnerlutzi zu meinem Standardsystem machen reicht ein beadm activate donnerlutzi und es wird ab dem nächsten Booten immer als erste Wahl in Grub angezeigt.
Sehr praktisch ist das ich diese Bootumgebung auch separat aktualisieren oder komplett andere Software auf ihr installieren kann, da der Paketmanager damit umgehen kann (genauer genommen legt er sogar Sicherheitskopien meines Systems bei Updates an, so kann man immer wieder zurück wenn etwas schief geht. Dieses Verhalten kann man aber auch bei Bedarf umgehen).
Will ich jetzt eine Bootumgebung separat aktualisieren geht das wie folgt:
Aber da ich eigentlich ganz zufrieden mit meinen 2 derzeitigen Systemen bin will ich donnerlutzi jetzt ganz gerne wieder loswerden:
"Wozu braucht man so etwas jetzt?" Der erste Punkt ist sicherlich das man sich so sehr gut absichern kann wenn man mal sein System total zerbastelt oder Software installiert die stark ins System eingreift. Man kann immer wieder zurück und das mit Hilfe von ein paar Handgriffen ohne zeitaufwendiges Zurückspielen des Systems durch ein herkömmliches Backup. Man kann auch gleichzeitig die stabile und die Entwicklerversion des Systems auf meiner Platte haben ohne das sich beide in die Quere kommen. So kann man vorher schon testen was neue Versionen bringen werden ohne auf sein stabiles System verzichten zu müssen oder irgendwelche LiveCDs zu benutzen auf denen das testen meist eh nur eingeschränkt funktioniert.
"Wie funktioniert das ganze?" Beadm selbst ist in Python geschrieben und greift nur auf Möglichkeiten zurück die ZFS zur Verfügung stellt, also keine ekligen Hacks die irgendwelche großen Dumpdateien anlegen und dann irgendwie über 3 Ecken mounten, alles ist bereits sauber im System integriert. Beadm selber hat noch ein paar Funktionen die ich hier nicht erwähnt habe, ein Blick in die Manpage schafft hier aber Abhilfe.
Na dann viel Spaß beim hemmungslosen Basteln! Jetzt ohne Angst das danach nichts mehr funktioniert :)
[raichoo@itzkoatl:~]> beadm list
BE Active Mountpoint Space Policy Created
-- ------ ---------- ----- ------ -------
opensolaris_snv97 - - 55.57M static 2008-09-12 15:44
opensolaris_snv98 NR / 10.32G static 2008-09-19 07:25
Das sind also 2 Bootumgebungen. Wie man sieht belegt opensolaris_snv97 nur 55,57 MB an Plattenplatz obwohl es den KOMPLETTEN Zustand meines Systems (Anmerkung: Nur das System, mein Homefilesystem bleibt davon unberührt und kann auf jeder Instanz genutzt werden) vor dem letzten Upgrade repräsentiert. Diese Umgebung kann ich jetzt nach belieben vervielfältigen und damit weiterarbeiten oder einfach löschen wenn ich sie nicht mehr brauche. Was allerdings am wichtigsten ist: ich kann auf sie jederzeit zugreifen. Dies funktioniert fast genauso wie das händische mounten eines Datenträgers:
[raichoo@itzkoatl:~]> su
Password:
[root@itzkoatl:~]> mkdir /tmp/mountpoint
[root@itzkoatl:~]> beadm mount opensolaris_snv97 /tmp/mountpoint
[root@itzkoatl:~]> cd /tmp/mountpoint/
[root@itzkoatl:mountpoint]> ls
a/ etc/ mnt/ sbin/
bin@ export/ net/ system/
boot/ home/ opt/ tmp/
bootcd_microroot/ kernel/ platform/ usr/
cdrom/ lib/ proc/ var/
COPYRIGHT LICENSE rmdisk/
dev/ lost+found/ root/
devices/ media/ rpool/
[root@itzkoatl:mountpoint]> cd
[root@itzkoatl:~]> beadm unmount opensolaris_snv97
Man beachte das es hier unmount und nicht umount heißt ;)
Das erstellen und zerstören einer Bootumgebung ist ebenso einfach:
[root@itzkoatl:~]> beadm create donnerlutzi
[root@itzkoatl:~]> beadm list
BE Active Mountpoint Space Policy Created
-- ------ ---------- ----- ------ -------
donnerlutzi - - 80.5K static 2008-10-09 13:39
opensolaris_snv97 - - 55.57M static 2008-09-12 15:44
opensolaris_snv98 NR / 10.32G static 2008-09-19 07:25
Voila, das wars. Der Vorgang dauert satte 3 Sekunden und wie man sieht belegt donnerlutzi nur 80.5 KB an Plattenplatz. "Hmm... brauch ich da nicht noch einen Eintrag im Bootmanager damit ich in das System booten kann?" Nö, das macht beadm schon von ganz alleine ;)
[root@itzkoatl:~]> cat /rpool/boot/grub/menu.lst
...
#============ End of LIBBE entry =============
title donnerlutzi
bootfs rpool/ROOT/donnerlutzi
kernel$ /platform/i86pc/kernel/$ISADIR/unix -B $ZFS-BOOTFS
module$ /platform/i86pc/$ISADIR/boot_archive
#============ End of LIBBE entry =============
Will ich donnerlutzi zu meinem Standardsystem machen reicht ein beadm activate donnerlutzi und es wird ab dem nächsten Booten immer als erste Wahl in Grub angezeigt.
Sehr praktisch ist das ich diese Bootumgebung auch separat aktualisieren oder komplett andere Software auf ihr installieren kann, da der Paketmanager damit umgehen kann (genauer genommen legt er sogar Sicherheitskopien meines Systems bei Updates an, so kann man immer wieder zurück wenn etwas schief geht. Dieses Verhalten kann man aber auch bei Bedarf umgehen).
Will ich jetzt eine Bootumgebung separat aktualisieren geht das wie folgt:
[root@itzkoatl:~]> beadm mount donnerlutzi /tmp/mountpoint
[root@itzkoatl:~]> pkg -R /tmp/mountpoint image-update
...
Aber da ich eigentlich ganz zufrieden mit meinen 2 derzeitigen Systemen bin will ich donnerlutzi jetzt ganz gerne wieder loswerden:
[root@itzkoatl:~]> beadm unmount donnerlutzi
[root@itzkoatl:~]> beadm destroy donnerlutzi
Are you sure you want to destroy donnerlutzi? This action cannot be undone(y/[n]): y
[root@itzkoatl:~]> beadm list
BE Active Mountpoint Space Policy Created
-- ------ ---------- ----- ------ -------
opensolaris_snv97 - - 55.57M static 2008-09-12 15:44
opensolaris_snv98 NR / 10.32G static 2008-09-19 07:25
"Wozu braucht man so etwas jetzt?" Der erste Punkt ist sicherlich das man sich so sehr gut absichern kann wenn man mal sein System total zerbastelt oder Software installiert die stark ins System eingreift. Man kann immer wieder zurück und das mit Hilfe von ein paar Handgriffen ohne zeitaufwendiges Zurückspielen des Systems durch ein herkömmliches Backup. Man kann auch gleichzeitig die stabile und die Entwicklerversion des Systems auf meiner Platte haben ohne das sich beide in die Quere kommen. So kann man vorher schon testen was neue Versionen bringen werden ohne auf sein stabiles System verzichten zu müssen oder irgendwelche LiveCDs zu benutzen auf denen das testen meist eh nur eingeschränkt funktioniert.
"Wie funktioniert das ganze?" Beadm selbst ist in Python geschrieben und greift nur auf Möglichkeiten zurück die ZFS zur Verfügung stellt, also keine ekligen Hacks die irgendwelche großen Dumpdateien anlegen und dann irgendwie über 3 Ecken mounten, alles ist bereits sauber im System integriert. Beadm selber hat noch ein paar Funktionen die ich hier nicht erwähnt habe, ein Blick in die Manpage schafft hier aber Abhilfe.
Na dann viel Spaß beim hemmungslosen Basteln! Jetzt ohne Angst das danach nichts mehr funktioniert :)
AMP: Webentwicklungsumgebung für OpenSolaris
Für alle Web-Entwickler gibt es jetzt unter OpenSolaris eine umfangreiche Zusammenstellung an Entwicklungstools. Besonders interessant dürfte das zusammen mit Zones sein (einem Thema dem ich mich noch annehmen muss). Wie man AMP installiert und was es beinhaltet wird hier ausführlich erklärt. Das zusammen Dtrace (welches auch über PHP, JavaScript, Java, Python und Ruby tracing verfügt), ZFS und den bereits erwähnten Zones ergibt ein ziemliches Killerpaket.
Mittwoch, 8. Oktober 2008
ZFS Screencast
Ich habe auf Youtube gerade einen ganz interessanten ZFS Screencast gefunden. Leider verhaut sich der Präsentator ständig mit den Kommandos, dennoch nicht uninteressant wenn man ZFS noch nie im Einsatz auf einer WIRKLICH großen Kiste gesehen hat ;)
Samstag, 4. Oktober 2008
Samstag, 13. September 2008
ZSH Patch gegen fieses Memory Leak
Ich bin neulich auf einen unschönen Bug in ZSH gestoßen. Bei aktiviertem compinit wird bei jeder Vervollständigung ein Segment anonymer Speicher angelegt und nicht wieder richtig freigegeben. Ein kleines dtrace Skript hat das Problem entlarvt.
Danke an das ZSH-Team für das Überprüfen meines Patches.
#!/usr/sbin/dtrace -s
BEGIN
{
printf("\nTarget is : %d\nSegement is %X\n",$target, $1);
}
syscall::mmap64:return
/arg1 == $1 && pid == $target/
{
printf("mmap returns: %x",arg1);
self->triggered = 1;
}
pid$target:zsh:dupstring:return
/self->triggered == 1/
{
/*printf("Dupstring: %s",copyinstr(arg1));*/
self->triggered = 0;
}
syscall::mmap64:entry
/pid == $target/
{
printf("mmap size: %d",arg1);
}
syscall::munmap:entry
/arg0 == $1 && pid == $target/
{
printf("munmap size: %d\n",arg1);
ustack();
self->munmapping = 1;
}
syscall::munmap:return
/self->munmapping/
{
printf("Result of munmapping the segment in question was: %d",arg1);
self->munmapping = 0;
}
fbt::as_removeseg:entry
/execname == "zsh" && ((struct seg*)arg1)->s_base == (caddr_t)$1/
{
printf("\nGot removed");
ustack();
stack();
exit(0);
}
fbt::as_addseg:entry
/execname == "zsh" && ((struct seg*)arg1)->s_base == (caddr_t)$1/
{
printf("\nGot added");
ustack();
stack();
}
Danke an das ZSH-Team für das Überprüfen meines Patches.
Index: Src/mem.c
===================================================================
RCS file: /cvsroot/zsh/zsh/Src/mem.c,v
retrieving revision 1.16
diff -u -p -r1.16 mem.c
--- Src/mem.c 17 May 2008 17:55:38 -0000 1.16
+++ Src/mem.c 7 Sep 2008 09:23:32 -0000
@@ -153,9 +153,9 @@ old_heaps(Heap old)
n = h->next;
DPUTS(h->sp, "BUG: old_heaps() with pushed heaps");
#ifdef USE_MMAP
- munmap((void *) h, sizeof(*h));
+ munmap((void *) h, h->size);
#else
- zfree(h, sizeof(*h));
+ zfree(h, HEAPSIZE);
#endif
}
heaps = old;
ZSH: IPS Completion Skript
So ich hab mich mal hingesetzt und ein Vervollständigungsskript für IPS in der ZSH geschrieben. Das ganze ist noch relativ frisch und deswegen klappt vielleicht noch nicht alles so wie es soll, also gilt wie immer: PATCHES WELCOME ;)
IPS Completion
Um es zu nutzen: einfach als _pkg in /usr/share/zsh/site-functions speichern (compinit muss dafür aktiviert sein)
Gegebenenfalls werde ich das Skript natürlich aktualisieren. Ich habe leider noch nicht rausbekommen wie man Google Docs verbieten kann die Einrückung einfach zu verschlucken, also sieht das ganze dementsprechend schrecklich aus. Ich hoffe mal das es trotzdem noch ohne Probleme funktionieren wird.
IPS Completion
Um es zu nutzen: einfach als _pkg in /usr/share/zsh/site-functions speichern (compinit muss dafür aktiviert sein)
Gegebenenfalls werde ich das Skript natürlich aktualisieren. Ich habe leider noch nicht rausbekommen wie man Google Docs verbieten kann die Einrückung einfach zu verschlucken, also sieht das ganze dementsprechend schrecklich aus. Ich hoffe mal das es trotzdem noch ohne Probleme funktionieren wird.
Sonntag, 24. August 2008
Dtrace im Kampfeinsatz: ZSH debuggen
Ich bin ja vor kurzem auf die wunderbare ZSH umgestiegen und leider Gottes habe ich den ein oder anderen Bug gefunden der ziemlich nervig ist. Es wurde mir verweigert selbst geschriebene Widgets an die menuselect Keymap zu binden. Naja, was macht man da? Ganz einfach, Sourcecode besorgen und dtrace durchstarten lassen. Nach kurzer Zeit hatte ich das Problem eingekreist und konnte mich ohne Probleme auf den relevanten Teil konzentrieren ohne erst großartig den Code zu lesen. In einem Fenster hatte ich die zu debuggende Shell in der anderen lief dtrace und hat mir angezeigt was passiert während ich tippe.
Hier sind ein paar Skripte die ich verwendet habe:
Was passiert gerade im Z-Lineeditor:
Der Userstack Backtrace sobald
Und das ganze nochmal für
Das ganze lief am Ende darauf hinaus das im aktuellen Source der Version 4.3.6 einfach die Zeile 2315 in der Datei complist.c von
Auf jeden Fall kann ich jetzt selbst geschriebene Widgets an die menuselect Keymap binden und $KEYMAP wird beim Wechsel auch richtig gesetzt, alles ohne viel Aufwand oder einer Debugversion von ZSH :D. Mal sehen was Upstream dazu sagt.
Ich sage dazu nur: DTRACE ROCKT!
Hier sind ein paar Skripte die ich verwendet habe:
Was passiert gerade im Z-Lineeditor:
#!/usr/sbin/dtrace -s
#pragma D option flowindent
pid$target:zle.so::entry,
pid$target:zle.so::return
{
}
Der Userstack Backtrace sobald
selectkeymap aufgerufen wird, inklusive der Information um welche Keymap es sich handelt:
#!/usr/sbin/dtrace -s
pid$target:zle.so:selectkeymap:entry
{
ustack();
printf("%s",copyinstr(arg0));
}
Und das ganze nochmal für
selectlocalmap:
#!/usr/sbin/dtrace -s
pid$target:zle.so:selectlocalmap:entry
/arg0 != 0/
{
ustack();
printf("%p",arg0);
}
Das ganze lief am Ende darauf hinaus das im aktuellen Source der Version 4.3.6 einfach die Zeile 2315 in der Datei complist.c von
selectlocalmap(mskeymap) in selectkeymap("menuselect",1) geändert werden musste. Da das ganze ein ziemlicher Quickhack ist, übernehme ich aber für nichts die Garantie ;).Auf jeden Fall kann ich jetzt selbst geschriebene Widgets an die menuselect Keymap binden und $KEYMAP wird beim Wechsel auch richtig gesetzt, alles ohne viel Aufwand oder einer Debugversion von ZSH :D. Mal sehen was Upstream dazu sagt.
Ich sage dazu nur: DTRACE ROCKT!
Samstag, 23. August 2008
ZSH: vi-mode reloaded
Hmmmmm, vi Kommandos in der Shell. Sowas macht doch Spaß. Allerdings hab ich es gerne wenn mir der aktuelle Mode angezeigt und der Shellprompt ausgeblendet wird sobald ich im Kommando-Modus bin. Dafür hab ich meine .zshrc etwas erweitert. Allerdings gibt es ein kleines Problem: Der RPROMPT wird nur angepasst wenn die Shell mindestens ein Kommando ausgeführt hat. Mal sehen was die ZSH-Mailinglist dazu sagt.
zle-line-init zle-keymap-select()
{
RPROMPT=${${KEYMAP/vicmd/-- COMMAND --}/main/}
PROMPT=${${KEYMAP/main/$SAVEDPROMPT}/vicmd/}
zle reset-prompt
}
zle -N zle-line-init
zle -N zle-keymap-select
setopt TRANSIENTRPROMPT
bindkey -M vicmd "^M" down-line-or-history
Donnerstag, 21. August 2008
ZSH: Fit for fun
Heute hab ich mich von der guten alten BASH verabschiedet und mein System auf ZSH umgestellt. Und da so eine mächtige Shell auch hübsch aussehen soll habe ich ihr auch gleich einen netten Look verpasst.

Für alle die es interessiert, hier die .zshrc:
Als kleine Besonderheit habe ich ls so umgestellt das es im Normalfall das GNU dir nimmt (weil das so schön bunt ist :P) und sobald ich die Option -v oder -V verwende das Solaris ls (weil das mit NFSv4 ACLs klarkommt welche ZFS-Standard sind)

Für alle die es interessiert, hier die .zshrc:
# Lines configured by zsh-newuser-install
HISTSIZE=1000
SAVEHIST=1000
# End of lines configured by zsh-newuser-install
PATH="/usr/bin:\
/usr/X11/bin:\
/usr/sbin:/sbin:\
/opt/SunStudioExpress/bin:\
/opt/netbeans-6.0/bin:\
/opt/DTT/Bin:\
/usr/sfw/bin:\
/usr/gnu/bin"
MANPATH="/usr/share/man:\
/usr/X11/share/man:\
/opt/SunStudioExpress/man:\
/opt/DTT/Man:\
/usr/sfw/share/man:\
/usr/gnu/share/man"
if ((EUID != 0));
then
PROMPT="[%{$(echo -n '\e[1;32m')%}%n\
%{$(echo -n '\e[0;00m')%}@\
%{$(echo -n '\e[0;33m')%}%m\
%{$(echo -n '\e[0;00m')%}:\
%{$(echo -n '\e[0;34m')%}%1~\
%{$(echo -n '\e[0;00m')%}]\
%{$(echo -n '\e[0;34m')%}> \
%{$(echo -n '\e[0;00m')%}"
HISTFILE=~/.histfile
else
PROMPT="[%{$(echo -n '\e[0;31m')%}%n\
%{$(echo -n '\e[0;00m')%}@\
%{$(echo -n '\e[0;33m')%}%m\
%{$(echo -n '\e[0;00m')%}:\
%{$(echo -n '\e[0;34m')%}%~\
%{$(echo -n '\e[0;00m')%}]\
%{$(echo -n '\e[0;31m')%}> \
%{$(echo -n '\e[0;00m')%}"
HISTFILE="/root/.histfile"
fi
ls()
{
if [[ ${1[0,2]} != "-v" ]] && [[ (${1[0,2]} != "-V") ]];
then
/bin/dir $argv --color=always
else
/bin/ls $argv
fi
}
setopt HIST_IGNORE_DUPS
setopt VI
unsetopt flowcontrol
bindkey "^[[3~" delete-char
Als kleine Besonderheit habe ich ls so umgestellt das es im Normalfall das GNU dir nimmt (weil das so schön bunt ist :P) und sobald ich die Option -v oder -V verwende das Solaris ls (weil das mit NFSv4 ACLs klarkommt welche ZFS-Standard sind)
Mittwoch, 20. August 2008
Dtrace Workshop - Teil 4: Userspace tracen mit dem PID-Provider
Nachdem wir uns in den letzten drei Teilen eigentlich nur mit Kerneltracing befasst haben, wird es Zeit sich dem Userspace zu widmen. Hierfür liefert dtrace den PID-Provider mit dem wir jede Funktion innerhalb eines Prozesses genauso unter die Lupe nehmen können wie wir es auch schon beim Kernel gelernt haben. Diesen Provider werde ich jetzt anhand eines einfachen C-Programms vorstellen.
Dieses Programm werden wir komplett ohne Debugsymbole übersetzen und userspace nennen. Wir wollen jetzt mit dem PID-Provider sehen welche Funktionen innerhalb des Programms ausgeführt werden. Dazu schreiben wir ein einfaches D Skript.
Die Variable $target bezieht sich auf das Programm das wir für dtrace als Ziel angeben. Dieses können wir mir der -c Option für ein spezifisches Kommando, oder mit -p für eine bestimmte PID angeben. Normal setzt sich der PID-Provider aus dem Wort pid und einer PID zusammen (z.B. pid2342), mit der Zielvariablen ist unser Skript allerdings sehr viel dynamischer. Als Modul haben wir hier userspace angegeben. Das ist der Name unseres Programms. Wir werden also nur Funktionen tracen die wir innerhalb unseres Programms definiert haben. Mit dtrace -l -p pidPID kann man sich übrigens alle tracebaren Funktionen eines bestimmten Prozesses ausgeben lassen (aber vorsicht, das ist meistens echt viel ;) ).
Jetzt würden wir aber gerne noch unsere printfs mittracen, dazu erweitern wir unser Skript einfach um die Tupel pid$target:libc.so.1:printf:entry und pid$target:libc.so.1:printf:return um die in libc.so.1 definierte printf Funktion zu tracen (das geht auch für jede andere gelinkte lib). Wir erhalten nun folgende Ausgabe:
Somit können wir jetzt jede Userspace Funktion tracen. Zum Abschluss will ich noch zeigen wie wir hier auch Probeargumente anwenden können:
#include <stdio.h>
void a(int i)
{
printf("a\n");
return;
}
void b(int i)
{
printf("b\n");
a(3);
}
void c(int i)
{
printf("c\n");
b(2);
}
int main()
{
c(1);
return 0;
}
Dieses Programm werden wir komplett ohne Debugsymbole übersetzen und userspace nennen. Wir wollen jetzt mit dem PID-Provider sehen welche Funktionen innerhalb des Programms ausgeführt werden. Dazu schreiben wir ein einfaches D Skript.
#!/usr/sbin/dtrace -s
#pragma D option flowindent
pid$target:userspace::return,
pid$target:userspace::entry
{
}
Die Variable $target bezieht sich auf das Programm das wir für dtrace als Ziel angeben. Dieses können wir mir der -c Option für ein spezifisches Kommando, oder mit -p für eine bestimmte PID angeben. Normal setzt sich der PID-Provider aus dem Wort pid und einer PID zusammen (z.B. pid2342), mit der Zielvariablen ist unser Skript allerdings sehr viel dynamischer. Als Modul haben wir hier userspace angegeben. Das ist der Name unseres Programms. Wir werden also nur Funktionen tracen die wir innerhalb unseres Programms definiert haben. Mit dtrace -l -p pidPID kann man sich übrigens alle tracebaren Funktionen eines bestimmten Prozesses ausgeben lassen (aber vorsicht, das ist meistens echt viel ;) ).
raichoo@itzkoatl:~/Projects# ./userspacetrace.d -c ./userspace
dtrace: script './userspacetrace.d' matched 13 probes
c
b
a
CPU FUNCTION
0 -> _start
0 -> __fsr
0 <- __fsr
0 -> main
0 -> c
0 -> b
0 -> a
0 <- a
0 <- b
0 <- c
0 <- main
dtrace: pid 697 has exited
Jetzt würden wir aber gerne noch unsere printfs mittracen, dazu erweitern wir unser Skript einfach um die Tupel pid$target:libc.so.1:printf:entry und pid$target:libc.so.1:printf:return um die in libc.so.1 definierte printf Funktion zu tracen (das geht auch für jede andere gelinkte lib). Wir erhalten nun folgende Ausgabe:
dtrace: script './userspacetrace.d' matched 15 probes
c
b
a
CPU FUNCTION
0 -> _start
0 -> __fsr
0 <- __fsr
0 -> main
0 -> c
0 -> printf
0 <- printf
0 -> b
0 -> printf
0 <- printf
0 -> a
0 -> printf
0 <- printf
0 <- a
0 <- b
0 <- c
0 <- main
dtrace: pid 714 has exited
Somit können wir jetzt jede Userspace Funktion tracen. Zum Abschluss will ich noch zeigen wie wir hier auch Probeargumente anwenden können:
#!/usr/sbin/dtrace -s
#pragma D option flowindent
pid$target:userspace::entry
{
printf("Funktionsargument %d",arg0);
}
pid$target:userspace::return,
pid$target:libc.so.1:printf:return
{
}
pid$target:libc.so.1:printf:entry
{
printf("Funktionsargument %s",copyinstr(arg0));
}
Dienstag, 19. August 2008
Dtrace Workshop - Teil 3: Der FBT-Provider und erste dtrace-Skripte
In Teil 1 angekündigt und in Teil 2 aufgeschoben will ich jetzt endlich zum FBT-Provider kommen. Hiermit kann man sich wie gesagt jede Funktion die es im Kernel gibt ausgeben lassen. Als Beispiel werden wir uns hier angucken was im Kernel passiert wenn wir bestimmte Systemcalls ausführen. Da unsere dtrace Anweisungen aber inzwischen immer komplexer werden, wird es langsam Zeit das wir uns damit befassen wie man dtrace Skripte schreibt.
Wie bereits mehrmals gesagt wurde handelt es sich bei D um eine eigene Programmiersprache handelt welche sich an AWK und C anlehnt. D ist eventgesteuert, das heißt das bei bestimmten Ereignissen etwas ausgeführt wird und der Code nicht einfach durchlaufen wird. Als ersten sehen wir und mal ein einfaches dtrace Skript an. Wir greifen dabei auf eine der ersten Lektionen zurück die wir hatten, nämlich wie man sich anzeigen läßt welcher Prozess gerade welchen Systemcall ausführt.
Wir speichern das ganze unter syscall.d und machen es mit chmod +x syscall.d ausführbar. Das Resultat sieht dann wie folgt aus:
Voila, schon haben wir unsere "Mühe" permanent in ein Skript gepackt, immer wieder abrufbar :).
Wollen wir uns jetzt mal ein etwas komplexeres D Skript ansehen. Hier werden wir uns ansehen was beim mmap Syscall alles im Kernel passiert.
Ok das ist jetzt etwas viel auf einmal. Besonders mysteriös ist hier die Zeile self->verfolgen = 1. Hierbei handelt es sich um eine theadlokale Variable. Ruft ein Thread mmap auf wird verfolgen für diesen Thread auf 1 gesetzt, das wird wichtig wenn wir die Bedingung für unsere FBT Probes ansehen, diese wird nämlich nur ausgeführt wenn self->verfolgen gesetzt ist. Erinnern wir uns: in Teil 1 haben wir festgestellt das D Events wie folgt aufgebaut sind:
Sobald der mmap Systemcall zurückkehrt (mit syscall::mmap:return) wird die Variabel auf 0 gesetzt und das Skript beendet. Gucken wir uns mal die Ausgabe dieses Skripts an:
Ok das ist ein ziemlicher Rattenschwanz (natürlich habe ich die Ausgabe hier gekürzt ;) )und leider auch sehr unübersichtlich, aber das alles passiert innerhalb eines mmap Syscalls im Kernel. Es wäre aber doch viel schöner wenn man die Ausgabe etwas einrücken könnte und damit besser lesbar. Das erreichen wir durch eine zusätzliche Zeile in unserem Skript.
Durch die Anweisung #pragma D option flowindent veranlassen wir dtrace unsere Ausgabe je nach entry oder return einzurücken und somit sehr viel lesbarer zu machen.
Hier nochmal die gleiche Ausagebe mit flowindent:
Jetzt kann man sicher sagen: "Ok... das sagt mir zwar jetzt welche Funktionen ausgeführt werden, aber was passiert denn jetzt genau". Stimmt, ohne Code sagt uns das jetzt recht wenig. Sun hat allerdings unter http://src.opensolaris.org/source/ den gesamten veröffentlichen Code durchsuchbar gemacht. Wir brauchen uns also nur eine Funktion von Interesse aussuchen, ihren Namen unter Definition eingeben und schon kriegen wir die Datei angegeben in der sie definiert ist und können sie uns auch online ansehen. Zugegeben ist das keine leichte Kost, aber das ist Kernelcode eigentlich fast nie. Hier kann man ihn aber live in Aktion sehen was das Verständnis um einiges erleichtert. :)
Wie bereits mehrmals gesagt wurde handelt es sich bei D um eine eigene Programmiersprache handelt welche sich an AWK und C anlehnt. D ist eventgesteuert, das heißt das bei bestimmten Ereignissen etwas ausgeführt wird und der Code nicht einfach durchlaufen wird. Als ersten sehen wir und mal ein einfaches dtrace Skript an. Wir greifen dabei auf eine der ersten Lektionen zurück die wir hatten, nämlich wie man sich anzeigen läßt welcher Prozess gerade welchen Systemcall ausführt.
#!/usr/sbin/dtrace -s
syscall:::entry
{
trace(execname);
}
Wir speichern das ganze unter syscall.d und machen es mit chmod +x syscall.d ausführbar. Das Resultat sieht dann wie folgt aus:
raichoo@itzkoatl:~# ./syscall.d
dtrace: script './syscall.d' matched 233 probes
CPU ID FUNCTION:NAME
0 68998 ioctl:entry dtrace
0 68998 ioctl:entry dtrace
0 69134 sysconfig:entry dtrace
0 69134 sysconfig:entry dtrace
0 69266 schedctl:entry dtrace
0 69068 sigaction:entry dtrace
0 69068 sigaction:entry dtrace
0 69068 sigaction:entry dtrace
0 69068 sigaction:entry dtrace
...
Voila, schon haben wir unsere "Mühe" permanent in ein Skript gepackt, immer wieder abrufbar :).
Wollen wir uns jetzt mal ein etwas komplexeres D Skript ansehen. Hier werden wir uns ansehen was beim mmap Syscall alles im Kernel passiert.
#!/usr/sbin/dtrace -s
syscall::mmap:entry
{
self->verfolgen = 1;
}
fbt:::entry,
fbt:::return
/self->verfolgen/
{
}
syscall::mmap:return
{
self->verfolgen = 0;
exit(0);
}
Ok das ist jetzt etwas viel auf einmal. Besonders mysteriös ist hier die Zeile self->verfolgen = 1. Hierbei handelt es sich um eine theadlokale Variable. Ruft ein Thread mmap auf wird verfolgen für diesen Thread auf 1 gesetzt, das wird wichtig wenn wir die Bedingung für unsere FBT Probes ansehen, diese wird nämlich nur ausgeführt wenn self->verfolgen gesetzt ist. Erinnern wir uns: in Teil 1 haben wir festgestellt das D Events wie folgt aufgebaut sind:
probe-tupel
/Bedingung/
{
Funktionskörper
}
Sobald der mmap Systemcall zurückkehrt (mit syscall::mmap:return) wird die Variabel auf 0 gesetzt und das Skript beendet. Gucken wir uns mal die Ausgabe dieses Skripts an:
raichoo@itzkoatl:~# ./mmap.d
dtrace: script './mmap.d' matched 66380 probes
CPU ID FUNCTION:NAME
0 31880 smmap32:entry
0 23175 smmap_common:entry
0 27816 as_rangelock:entry
0 27817 as_rangelock:return
0 23173 zmap:entry
0 31698 choose_addr:entry
0 21835 map_addr:entry
...
0 29853 as_map:return
0 23174 zmap:return
0 29415 as_rangeunlock:entry
0 29952 cv_signal:entry
0 29953 cv_signal:return
0 29416 as_rangeunlock:return
0 23176 smmap_common:return
0 31881 smmap32:return
0 69093 mmap:return
Ok das ist ein ziemlicher Rattenschwanz (natürlich habe ich die Ausgabe hier gekürzt ;) )und leider auch sehr unübersichtlich, aber das alles passiert innerhalb eines mmap Syscalls im Kernel. Es wäre aber doch viel schöner wenn man die Ausgabe etwas einrücken könnte und damit besser lesbar. Das erreichen wir durch eine zusätzliche Zeile in unserem Skript.
#!/usr/sbin/dtrace -s
#pragma D option flowindent
syscall::mmap:entry
{
self->verfolgen = 1;
}
fbt:::entry,
fbt:::return
/self->verfolgen/
{
}
syscall::mmap:return
{
self->verfolgen = 0;
exit(0);
}
Durch die Anweisung #pragma D option flowindent veranlassen wir dtrace unsere Ausgabe je nach entry oder return einzurücken und somit sehr viel lesbarer zu machen.
Hier nochmal die gleiche Ausagebe mit flowindent:
raichoo@itzkoatl:~# ./mmap.d
dtrace: script './mmap.d' matched 66380 probes
CPU FUNCTION
0 -> smmap32
0 -> smmap_common
0 -> as_rangelock
0 <- as_rangelock
0 -> zmap
0 -> choose_addr
0 -> map_addr
...
0 <- zmap
0 -> as_rangeunlock
0 -> cv_signal
0 <- cv_signal
0 <- as_rangeunlock
0 <- smmap_common
0 <- smmap32
0 <= mmap
Jetzt kann man sicher sagen: "Ok... das sagt mir zwar jetzt welche Funktionen ausgeführt werden, aber was passiert denn jetzt genau". Stimmt, ohne Code sagt uns das jetzt recht wenig. Sun hat allerdings unter http://src.opensolaris.org/source/ den gesamten veröffentlichen Code durchsuchbar gemacht. Wir brauchen uns also nur eine Funktion von Interesse aussuchen, ihren Namen unter Definition eingeben und schon kriegen wir die Datei angegeben in der sie definiert ist und können sie uns auch online ansehen. Zugegeben ist das keine leichte Kost, aber das ist Kernelcode eigentlich fast nie. Hier kann man ihn aber live in Aktion sehen was das Verständnis um einiges erleichtert. :)
Montag, 18. August 2008
Warum OpenSolaris?
Ich muss zugeben das mir diese Frage in den letzten Wochen ziemlich oft gestellt wurde, vor allem da man mich seit 12 Jahren eigentlich als überzeugten Linuxuser kannte. Zugegeben hat mich das ganze selbst ziemlich unerwartet getroffen, da ich OpenSolaris bis auf ZFS eigentlich als ziemlich uninteressant empfunden habe und teilweise sogar belächelt. Aber mit Betriebssystemen ist es manchmal wie mit Menschen: "Wenn man es erst einmal kennengelernt hat, ist es eigentlich richtig cool".
"Aber warum nicht Linux?"
, hört man aus der Linuxecke (bei den BSDler ist es oft ähnlich ^^). Die Frage ist sicherlich nicht ganz unberechtigt, verfügt Linux doch über sehr viel mehr Treiber und je nach Distribution derzeit noch über sehr viel mehr Pakete. Das mit den Treiber ist tatsächlich immer wieder ein Argument welches mir begegnet. Die Sache mit Treiber ist allerdings: Man braucht sie nur wenn man die Hardware hat. Und 99% der unterstützten Hardware besitze ich nun mal nicht und ich habe genauso wenig vor sie zu kaufen, also ist das Treiberargument hinfällig. Außerdem erinnere ich mich noch an eine Zeit als ich unter Linux weder Sound noch einen brauchbaren Browser hatte und trotzdem habe ich es benutzt weil es eben das gemacht hat was ich von ihm verlangt habe.
Und genau das ist es was OpenSolaris jetzt für mich macht, derzeit allerdings noch mehr als Entwicklungsumgebung und noch nicht als mein Alltagsdesktop da es unter anderem noch an einer gewissen Multimediafähigkeit mangelt. Da OpenSolaris in dieser Form allerdings erst seit Mai existiert und es dafür schon eine sehr vollständige Figur macht, kann ich darüber ersteinmal hinwegsehen. Außerdem ist besagtes für den nächsten Release im November in Arbeit.
"Aber was macht OpenSolaris denn jetzt besser als Linux?"
Erstmal: Es handelt sich hier um persönliche Präferenzen. Ich kann hier noch soviel von Features schwärmen, aber letztendlich muss man diese Features auch nutzen. Hier einfach mal ein kleiner Einblick:
ZFS
In den letzten Monaten ist ZFS schon fast zum Buzzword geworden. Irgendwie redet jeder davon aber selten wird wirklich mal erklärt was ZFS eigentlich kann. Für alle Interessenten kann ist jedem Mal den ZFS Podcast vom Chaosradio ans Herz legen. Ein besonders tolles Feature bei ZFS ist die Möglichkeit Snapshots von seinen Filesystemen anzulegen und damit sein System ähnlich wie bei modernen Versionskontrollsystemen zu verzweigen. Hier ein Beispiel von meinem System.
Es verfügt über 2 sogenannte Bootumgebungen. opensolaris und opensolaris_snv95. Auf der ersten liegt das Ursystem, mit anderen Worten die Version von OpenSolaris mit der ich installiert habe. Mit der Zeit kamen allerdings mehrere Updates und wie heißt es so schön: "Never change a winning Team". Also habe ich eine zusätzliche Bootumgebung mit dem Namen opensolaris_snv95 angelegt. Nachdem man diese erzeugt hat, besitzt man eine exakte Kopie seines Systems welche man dann separat updaten kann. Das ganze funktioniert so:
Mit pkg habe ich die Kopie meines Systems auf den neusten Stand gebracht und mit activate habe ich dafür gesorgt das sie beim nächsten booten als Standard ausgewählt wird. Besonders praktisch ist hier das beadm auch schon grub eingerichtet hat und ich jetzt für jede Version einen Eintrag hat. Dazu kommt noch das die Kopie meines Systems nur den Unterschied zwischen beiden Systemen an Plattenplatz belegt. So kann man immer ohne Risiko an seinem System herumschrauben und mit einem Handgriff zurück. Aber ZFS kann noch mehr, unter anderem auch unglaublich mächtige Backupfunktionen, sehr komfortables NFS und Samba-Management, Raidfunktionen die weit über die Möglichkeit von traditionellem Hardwareraid hinausgehen, transparente Kompression und bald auch transparente Verschlüsselung, Selbstheilung und alles läßt sich mit zwei Befehlen einfach und intuitiv aus der Konsole steuern. Wers nicht glaubt, hier die manpages zu zpool und zfs.
Dtrace und MDB
Ich bin jemand der gerne versteht was in seinem System vorgeht. Das schließt Userspace Programme genauso ein wie Kernelspace Aktivitäten. Aus diesem Grund sammel ich auch Bücher die sich mit den jeweiligen Kerneln befassen. Zu Linux besitze ich das Buch "Understanding the Linux Kernel", und auch wenn es in vielerlei Hinsicht nicht uninteressant ist hat es einen gravierenden Nachteil: Ich kann so gut wie nichts davon live beobachten und mir bringt das Wissen um den Kernel und seine Funktionsweise relativ wenig, da nachdem er übersetzt ist er sich für mich in eine Blackbox verwandelt. Mit dtrace und dem Modular Debugger mdb kann ich jederzeit in den Kernel hineinsehen und nachvollziehen was passiert. Ich kann mein Wissen über den Kernel einsetzen um an die Informationen heranzukommen die ich brauche. Ein extremer Vorteil wenn man Probleme sucht, oder einfach nur verstehen will was eigentlich vor sich geht. Zu dtrace haben ich, wie einige vielleicht schon bemerkt haben, einen Workshop auf meinem Blog, eventuell werde ich das gleiche auch noch für mdb machen.
IPS
Über die Jahre gab es viele Paketsysteme und inzwischen sind die etablierten mehr oder weniger veraltet. Rpm soll überholt werden und apt ist für meinem Geschmack einfach zu kompliziert wenn es ums schnüren von Paketen geht. Ich will meine Software einfach nur übersetzen und dann freigeben können. Genau das macht IPS für mich. Ich muss mich nicht damit befassen Skripte zu schreiben um ein Paket zu erschaffen sondern kann meine Software einfach in mein eigenes Repository hochladen, das ganze ist in der Funktionalität wieder stark an moderne Versionskontrollsysteme angelehnt. Alles wunderbar ist dokumentiert auf der OpenSolaris Seite.
Dokumentation
Womit wir auch gleich schon zum nächsten Punkt kommen. Als Developer hasst man es sie zu schreiben, als Anwender liebt man es sie zu haben. Dokumentation. Was mich bei praktisch allen Linux Distributionen immer gestört hat war der Mangel an aktueller tiefgreifender Dokumentation, die auch zugegebenermaßen bei den vielen Änderungen (ob nötig oder nicht sei mal dahingestellt) oft nicht auf dem neusten Stand ist oder teilweise einfach nur oberflächlich am Problem kratzt. Meistens provoziert ein sogenanntes Howto noch weitere Fragen die wieder dazu führen das man suchen muss. Das ganze artet oft in eine Art Schnitzeljagd im Netz aus, die nicht immer vom Erfolg gekrönt ist und gerade bei komplexen Fragen oft im Nichts endet.
Zu Solaris gibt es allerdings einen zentralen Dokumentationsserver. http://docs.sun.com wartet mit einem Berg an Büchern auf (ja, ganze Bücher keine Howtos)die alle frei zum herunterladen angeboten werden. Alles im handlichen PDF Format, sprengt das Angebot ohne Probleme die 10.000 Seiten Grenze (vermutlich sogar weit darüber hinaus). Alles wird verständlich mit Beispielen erklärt und sollte doch mal eine Frage auftauchen existiert meistens schon ein Link zum Buch das diese Frage klärt.
Stabile ABI
Etwas vor dem sich Linux leider bis heute fürchtet oder ablehnt. Oft sind nach 2 oder 3 Versionen Treiber im Binärformat nicht mehr zu gebrauchen und man muss praktisch alles neu kompilieren. Nutzt man eine vorgefertigte Distribution hat man dieses Problem nicht, aber kommerzielle Anbieter schrecken davor zurück Treiber für Linux herzustellen da die Binärkompatibilität nicht gewährleistet ist. Auch wenn ich prinzipiell gegen sogenannte Blobs bin ist es für viele Anbieter ein Grund keine Treiber für Linux zu veröffentlichen, da der Wartungsaufwand in keinerlei Bezug zum Nutzen wäre. Unter Solaris 10 z.B. ist es allerdings immer noch möglich einen Netzwerktreiber zu laden der für Solaris 8 geschrieben wurde.
Es gibt noch viele weitere Grunde wie das SMF System, Zones, die SunStudio Entwicklungsumgebung, die p*-Tools usw. Die mich dazu gebracht haben auf Solaris zu wechseln, aber auch hier gilt: Ein Feature ist nur dann sinnvoll wenn man es nutzt. Mir macht es auf jeden Fall das Leben ungeahnt leichter :)
Wer jetzt neugierig ist kann sich auch einmal den Podcast von pofacs.de (eine allgemein sehr lohnenswerte Seite) zu OpenSolaris anhören.

"Aber warum nicht Linux?"
, hört man aus der Linuxecke (bei den BSDler ist es oft ähnlich ^^). Die Frage ist sicherlich nicht ganz unberechtigt, verfügt Linux doch über sehr viel mehr Treiber und je nach Distribution derzeit noch über sehr viel mehr Pakete. Das mit den Treiber ist tatsächlich immer wieder ein Argument welches mir begegnet. Die Sache mit Treiber ist allerdings: Man braucht sie nur wenn man die Hardware hat. Und 99% der unterstützten Hardware besitze ich nun mal nicht und ich habe genauso wenig vor sie zu kaufen, also ist das Treiberargument hinfällig. Außerdem erinnere ich mich noch an eine Zeit als ich unter Linux weder Sound noch einen brauchbaren Browser hatte und trotzdem habe ich es benutzt weil es eben das gemacht hat was ich von ihm verlangt habe.
Und genau das ist es was OpenSolaris jetzt für mich macht, derzeit allerdings noch mehr als Entwicklungsumgebung und noch nicht als mein Alltagsdesktop da es unter anderem noch an einer gewissen Multimediafähigkeit mangelt. Da OpenSolaris in dieser Form allerdings erst seit Mai existiert und es dafür schon eine sehr vollständige Figur macht, kann ich darüber ersteinmal hinwegsehen. Außerdem ist besagtes für den nächsten Release im November in Arbeit.
"Aber was macht OpenSolaris denn jetzt besser als Linux?"
Erstmal: Es handelt sich hier um persönliche Präferenzen. Ich kann hier noch soviel von Features schwärmen, aber letztendlich muss man diese Features auch nutzen. Hier einfach mal ein kleiner Einblick:
ZFS
In den letzten Monaten ist ZFS schon fast zum Buzzword geworden. Irgendwie redet jeder davon aber selten wird wirklich mal erklärt was ZFS eigentlich kann. Für alle Interessenten kann ist jedem Mal den ZFS Podcast vom Chaosradio ans Herz legen. Ein besonders tolles Feature bei ZFS ist die Möglichkeit Snapshots von seinen Filesystemen anzulegen und damit sein System ähnlich wie bei modernen Versionskontrollsystemen zu verzweigen. Hier ein Beispiel von meinem System.
raichoo@itzkoatl:~$ beadm list
BE Active Active on Mountpoint Space
Name reboot Used
---- ------ --------- ---------- -----
opensolaris no no - 14.58M
opensolaris_snv95 yes yes / 6.40G
Es verfügt über 2 sogenannte Bootumgebungen. opensolaris und opensolaris_snv95. Auf der ersten liegt das Ursystem, mit anderen Worten die Version von OpenSolaris mit der ich installiert habe. Mit der Zeit kamen allerdings mehrere Updates und wie heißt es so schön: "Never change a winning Team". Also habe ich eine zusätzliche Bootumgebung mit dem Namen opensolaris_snv95 angelegt. Nachdem man diese erzeugt hat, besitzt man eine exakte Kopie seines Systems welche man dann separat updaten kann. Das ganze funktioniert so:
raichoo@itzkoatl:~# beadm create opensolaris_snv95
raichoo@itzkoatl:~# mkdir /tmp/mein_neues_system
raichoo@itzkoatl:~# beadm mount opensolaris_snv95 /tmp/mein_neues_system
raichoo@itzkoatl:~# pkg -R /tmp/mein_neues_system image-update
...
raichoo@itzkoatl:~# beadm unmount opensolaris_snv95
raichoo@itzkoatl:~# beadm activate opensolaris_snv95
Mit pkg habe ich die Kopie meines Systems auf den neusten Stand gebracht und mit activate habe ich dafür gesorgt das sie beim nächsten booten als Standard ausgewählt wird. Besonders praktisch ist hier das beadm auch schon grub eingerichtet hat und ich jetzt für jede Version einen Eintrag hat. Dazu kommt noch das die Kopie meines Systems nur den Unterschied zwischen beiden Systemen an Plattenplatz belegt. So kann man immer ohne Risiko an seinem System herumschrauben und mit einem Handgriff zurück. Aber ZFS kann noch mehr, unter anderem auch unglaublich mächtige Backupfunktionen, sehr komfortables NFS und Samba-Management, Raidfunktionen die weit über die Möglichkeit von traditionellem Hardwareraid hinausgehen, transparente Kompression und bald auch transparente Verschlüsselung, Selbstheilung und alles läßt sich mit zwei Befehlen einfach und intuitiv aus der Konsole steuern. Wers nicht glaubt, hier die manpages zu zpool und zfs.
Dtrace und MDB
Ich bin jemand der gerne versteht was in seinem System vorgeht. Das schließt Userspace Programme genauso ein wie Kernelspace Aktivitäten. Aus diesem Grund sammel ich auch Bücher die sich mit den jeweiligen Kerneln befassen. Zu Linux besitze ich das Buch "Understanding the Linux Kernel", und auch wenn es in vielerlei Hinsicht nicht uninteressant ist hat es einen gravierenden Nachteil: Ich kann so gut wie nichts davon live beobachten und mir bringt das Wissen um den Kernel und seine Funktionsweise relativ wenig, da nachdem er übersetzt ist er sich für mich in eine Blackbox verwandelt. Mit dtrace und dem Modular Debugger mdb kann ich jederzeit in den Kernel hineinsehen und nachvollziehen was passiert. Ich kann mein Wissen über den Kernel einsetzen um an die Informationen heranzukommen die ich brauche. Ein extremer Vorteil wenn man Probleme sucht, oder einfach nur verstehen will was eigentlich vor sich geht. Zu dtrace haben ich, wie einige vielleicht schon bemerkt haben, einen Workshop auf meinem Blog, eventuell werde ich das gleiche auch noch für mdb machen.
IPS
Über die Jahre gab es viele Paketsysteme und inzwischen sind die etablierten mehr oder weniger veraltet. Rpm soll überholt werden und apt ist für meinem Geschmack einfach zu kompliziert wenn es ums schnüren von Paketen geht. Ich will meine Software einfach nur übersetzen und dann freigeben können. Genau das macht IPS für mich. Ich muss mich nicht damit befassen Skripte zu schreiben um ein Paket zu erschaffen sondern kann meine Software einfach in mein eigenes Repository hochladen, das ganze ist in der Funktionalität wieder stark an moderne Versionskontrollsysteme angelehnt. Alles wunderbar ist dokumentiert auf der OpenSolaris Seite.
Dokumentation
Womit wir auch gleich schon zum nächsten Punkt kommen. Als Developer hasst man es sie zu schreiben, als Anwender liebt man es sie zu haben. Dokumentation. Was mich bei praktisch allen Linux Distributionen immer gestört hat war der Mangel an aktueller tiefgreifender Dokumentation, die auch zugegebenermaßen bei den vielen Änderungen (ob nötig oder nicht sei mal dahingestellt) oft nicht auf dem neusten Stand ist oder teilweise einfach nur oberflächlich am Problem kratzt. Meistens provoziert ein sogenanntes Howto noch weitere Fragen die wieder dazu führen das man suchen muss. Das ganze artet oft in eine Art Schnitzeljagd im Netz aus, die nicht immer vom Erfolg gekrönt ist und gerade bei komplexen Fragen oft im Nichts endet.
Zu Solaris gibt es allerdings einen zentralen Dokumentationsserver. http://docs.sun.com wartet mit einem Berg an Büchern auf (ja, ganze Bücher keine Howtos)die alle frei zum herunterladen angeboten werden. Alles im handlichen PDF Format, sprengt das Angebot ohne Probleme die 10.000 Seiten Grenze (vermutlich sogar weit darüber hinaus). Alles wird verständlich mit Beispielen erklärt und sollte doch mal eine Frage auftauchen existiert meistens schon ein Link zum Buch das diese Frage klärt.
Stabile ABI
Etwas vor dem sich Linux leider bis heute fürchtet oder ablehnt. Oft sind nach 2 oder 3 Versionen Treiber im Binärformat nicht mehr zu gebrauchen und man muss praktisch alles neu kompilieren. Nutzt man eine vorgefertigte Distribution hat man dieses Problem nicht, aber kommerzielle Anbieter schrecken davor zurück Treiber für Linux herzustellen da die Binärkompatibilität nicht gewährleistet ist. Auch wenn ich prinzipiell gegen sogenannte Blobs bin ist es für viele Anbieter ein Grund keine Treiber für Linux zu veröffentlichen, da der Wartungsaufwand in keinerlei Bezug zum Nutzen wäre. Unter Solaris 10 z.B. ist es allerdings immer noch möglich einen Netzwerktreiber zu laden der für Solaris 8 geschrieben wurde.
Es gibt noch viele weitere Grunde wie das SMF System, Zones, die SunStudio Entwicklungsumgebung, die p*-Tools usw. Die mich dazu gebracht haben auf Solaris zu wechseln, aber auch hier gilt: Ein Feature ist nur dann sinnvoll wenn man es nutzt. Mir macht es auf jeden Fall das Leben ungeahnt leichter :)
Wer jetzt neugierig ist kann sich auch einmal den Podcast von pofacs.de (eine allgemein sehr lohnenswerte Seite) zu OpenSolaris anhören.
Abonnieren
Posts (Atom)