Samstag, 29. November 2008
OpenSolaris in den HPC Top 500
Der erste OpenSolaris HPC ist in den Top 500 aufgetaucht und auf Platz 221 eingezogen. Bei dem guten Stück handelt es sich um ein Fujitsu System der Japan Aerospace Exploration Agency. Mehr dazu auf dem Sun HPC Blog.
Donnerstag, 27. November 2008
Compiz unter OpenSolaris
Und nun wieder mal was für die Kategorie "Cool aber nutzlos". Compiz ist nicht gerade ein Auswahlkriterium für mich wenn es um Betriebssysteme geht, aber es ist schon sehr hübsch anzuschauen. Darum habe ich mich mal hingesetzt und mein System etwas getrimmt.
Als erstes erstellen wir einfach eine xorg.conf. Xorg macht das automatisch wenn man als root Xorg -configure eingibt. Die erstellte config dann einfach nach /etc/X11/xorg.conf kopieren.
Nun haben wir folgendes Problem: Diese config verwendet als voreingestellte Beschleunigung EXA. Das ist auf meinem Intel Chip mehr als lahm und alles andere als weich und flüssig. Ein anderes Problem ist das in der Xorg Version von OpenSolaris die OffscreenPixmap Funktion per default aktiv ist, das sorgt für teilweise richtig eklige Grafikfehler. Also tragen wir folgendes in die Device Section ein:
Ok, jetzt einfach den X-Server neu starten und Compiz unter den visuellen Effekten aktivieren. Und voila: Es wird prollig ;)

Es könnte sein das man anstatt der Schatten am Panel große weiße Balken sieht. Die kann man aber loswerden indem man einfach die Schattengröße in den Compiz Einstellungen anpasst
Als erstes erstellen wir einfach eine xorg.conf. Xorg macht das automatisch wenn man als root Xorg -configure eingibt. Die erstellte config dann einfach nach /etc/X11/xorg.conf kopieren.
Nun haben wir folgendes Problem: Diese config verwendet als voreingestellte Beschleunigung EXA. Das ist auf meinem Intel Chip mehr als lahm und alles andere als weich und flüssig. Ein anderes Problem ist das in der Xorg Version von OpenSolaris die OffscreenPixmap Funktion per default aktiv ist, das sorgt für teilweise richtig eklige Grafikfehler. Also tragen wir folgendes in die Device Section ein:
Option "AccelMethod" "XAA"
Option "XAANoOffscreenPixmaps" "true"
Ok, jetzt einfach den X-Server neu starten und Compiz unter den visuellen Effekten aktivieren. Und voila: Es wird prollig ;)

Es könnte sein das man anstatt der Schatten am Panel große weiße Balken sieht. Die kann man aber loswerden indem man einfach die Schattengröße in den Compiz Einstellungen anpasst
Mittwoch, 26. November 2008
Uni Münster migriert zu ZFS
Nachdem wir neulich die Ankündigung bekommen haben das unsere Homeverzeichnisse an der Uni umziehen werden und wir in Zukunft einen gewaltigen Performanceboost kriegen, war ich doch mal neugierig was das zu bedeuten hat. Ein kleiner Blick auf unseren Fileserver hat mir folgendes gezeigt:
YAY!!!! Nuff said! :P (btw die Daten sind natürlich verfremdet ;)
pool: pool
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
pool ONLINE 0 0 0
mirror ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
errors: No known data errors
pool: pool2
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
pool2 ONLINE 0 0 0
raidz1 ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
raidz1 ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
cxtxdxsx ONLINE 0 0 0
errors: No known data errors
NAME SIZE USED AVAIL CAP HEALTH ALTROOT
pool 1.02T 321G 719G 30% ONLINE /
pool2 17.4T 1.59T 15.8T 9% ONLINE /
YAY!!!! Nuff said! :P (btw die Daten sind natürlich verfremdet ;)
Montag, 24. November 2008
OpenSolaris 2008.11 RC2 erschienen
Das ganze gibts auf www.genunix.org zum Runterladen. Bugs bitte auf defect.opensolaris.org melden.
Happy testing :)
Happy testing :)
Montag, 10. November 2008
Papa's got a brandnew pigbag!
Nachdem sich bei mir geradezu ein Rechnermaßensterben zugetragen hat, habe ich mir endlich ein neues Notebook geleistet. Das Lenovo Thinkpad SL500 hochgerüstet auf 4GB RAM: Das perfekte OpenSolaris Notebook. Das einzige was derzeit nicht unterstützt wird ist der Intel 5100 Wlan Chip und für den gibt es bereits Treiber (muss wohl nur noch lernen auch meine Karte zu erkennen, Bugreport ist bereits verschickt und akzeptiert :) ). Ansonsten geht wirklich alles vom Fingerabdruckscanner (naja... als wenns was bringen würde) bis zur Webcam :).

Anmerkung: Ja, den Desktop gibts auch in deutsch. Ich hab meinen allerdings immer englisch, sieht einfach besser aus.
Anmerkung: Ja, den Desktop gibts auch in deutsch. Ich hab meinen allerdings immer englisch, sieht einfach besser aus.
Mittwoch, 5. November 2008
Screencast: ZFS Selbstheilung
Wie ich schon in einem Artikel erwähnt habe, hat ZFS die Möglichkeit Fehler zu erkennen und diese auch selbst zu heilen. Für alle die das mal gerne in Aktion sehen wollen gibt es da einen interessanten Screencast ;). Man brauch auch nicht unbedingt einen Mirror dafür sondern kann einem ZFS sagen das es mehrere Kopien der Daten transparent angelegen soll (mit zfs set copies=n myzfs erzeugt das Filesystem myzfs n Kopien der Daten und kann korrumpierte Daten in Notfall rekonstruieren).
Screencast: ZFS Basics
Passend zu meiner Einführung in ZFS ist jetzt auch ein Screencast erschienen der ein paar der Funktionen von ZFS live zeigt. Immer wieder beeindruckend zu sehen wie schnell ZFS ist.

Dienstag, 4. November 2008
Mythbusting: $FOOFS + LVM = ZFS
Man hört es ja immer wieder wenn man ZFS erwähnt: "Das kann ich doch auch mit LVM machen!" oder "ZFS verletzt ja den ganzen Layergedanken, das gehört getrennt weils ja sonst total Bloatware ist". Damit möchte ich gerne mal in ein paar Punkten aufräumen, vor allem aber auch zeigen das diese Designentscheidung alles andere als willkürlich ist. Dazu werde ich 2 klassische ZFS Beispiele besprechen: Selbstheilung und Intelligentes Prefetching
Sehen wir uns erst einmal an wie ein Mirror auf herkömmliche Art und Weise angelegt ist:

Hier liegt eine klassische Trennung von Filesystem und Volumemanager vor. Das Filesystem hat keinerlei Ahnung das es auf einem Mirror arbeitet der Volumemanager liefert ihm einfach ein virtuelles Device und veranstaltet sein spiegeln unbemerkt vom Filesystem. Auf der anderen Seite kennt der Volumemanager sich aber auch nicht mit dem Filesystem aus, er arbeitet einfach nur mit abstrakten Daten die er wegschreibt und er nicht versteht da er keinerlei Bezug zum Filesystem hat.
ZFS ist hier in 3 Schichten aufgeteilt:
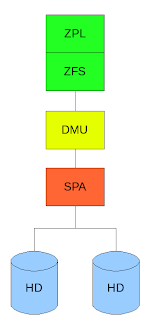
Dem ZFS Posix Layer (ZPL) welcher die normale Posix API zur Verfügung stellt (open,close,read,write etc) darunter liegt direkt das ZFS welches einzelne Transaktionen (ZFS arbeitet NUR mit Transaktionen, dass heißt das das Filesystem nie in einen inkonsistenten Zustand kommt) an die Data Management Unit (DMU) weitergibt welche viele Transaktionen zu einer großen zusammenfasst und der Storage Pool Allocator (SPA) welcher Kenntnis von den Platten (die in unserem Beispiel gespiegelt sind) hat.
Jetzt wollen wir als Beispiel auf einem Spiegel einen fehlerhaften Block haben welcher gelesen wird, sagen wir einfach mal es handelt sich hier um Metadaten welche durch äußere Einwirkungen (Erschütterung, Strahlung, statische Entladung etc) verändert wurden. Der Volumemanager hat hier keine Ahnung ob die Daten korrekt sind und reicht sie ans Filesystem weiter. Im schlimmsten Fall kommt es jetzt zu einer Kernelpanic im weniger schlimmen werden falsche Daten gelesen und die Applikation liefert falsche Ergebnisse oder stürzt ab. Da das Filesystem allerdings keinerlei Ahnung hat das es auf einem Mirror arbeitet kann es selbst wenn es bemerkt das die Daten falsch sind ja nicht wissen das evtl ein Mirror mit richtigen Daten existiert und keine korrekten Daten anfordern (da Volumemanager und Filesystem nun einmal voneinander getrennt sind).
Wie macht ZFS das nun? Als Erstes räumt das Design von ZFS mit dem immer noch verbreiteten Glauben auf das Prüfsummen teuer sind. Bei den heuten Rechnergeschwindigkeiten ist die Berechnung einer solchen Summe zeitlich gesehen zu vernachlässigen. Dies macht sich ZFS zu nutze und sichert JEDEN Block mit einer Prüfsumme (default 256-bit). ZFS erkennt also immer ob ein Block immer noch in dem gleichen Zustand auf der Platte liegt wie es ihn geschrieben hat.
Wir lesen nun den gleichen Block aus dem oberen Beispiel noch einmal. Durch die Prüfsumme erkennen wir das der Block falsch ist und da ZFS selber Kenntnis darüber hat das es auf einem Mirror arbeitet fordert es den gleichen Block von der anderen Platte erneut an. Dieser ist in unserem Beispiel korrekt worauf er an die Applikation weitergereicht wird während der andere fehlerhafte Block verworfen wird und mit dem korrekten von der anderen Platte automatisch überschrieben wird. Die Applikation merkt davon nicht das geringste. (Es ist sogar möglich eine der beiden Platte während eines Lese/Schreibvorgangs mit dd if=/dev/random zu überschreiben ohne das die Applikation fehlerhafte Daten zu sehen kriegt, gleichzeitig wird der Schaden den dd anrichtet transparent geheilt)

Hat man nur eine Festplatte zu Verfügung kann man durch zfs set copies=n filesystem veranlassen das alle Datenblöcke n-fach geschrieben werden. Tritt nun ein Fehler auf wird dieser genauso geheilt wie auf einem Mirror. Man kann so ein extra Filesystem für sehr sensible Daten absichern ohne mehrere Platten zur Verfügung zu haben (z.b. auf Notebooks).
Ein anderes beliebtes Beispiel ist der intelligente Prefetchmechanismus. Nehmen wir folgendes an: Auf einem Filesystem liegt eine Videodatei die gleichzeitig von mehreren Benutzern gelesen wird. Alles in allem sind dies sequentielle Lesezugriffe, da alle diese User jedoch eine andere Stelle der Datei lesen kann man hier mit der herkömmlichen Aufteilung kein sequentielles Pattern erkennen, hier kann also kein Prefetch stattfinden da nicht erkannt wird welcher Block als nächstes gelesen wird. Da ZFS allerdings den Userkontext hat kann es erkennen das es sich hier um mehrere sequentielle Reads handelt und dementsprechend optimieren für normale Filesysteme + Volumemanager bleibt dies aufgrund des mangelnden Kontexts eine zufällige Leseabfolge.
Dies sind nur ein paar Beispiele welche Vorteile das Zusammenlegen von Volumemanager und Filesystem hat, unter anderem kann man damit auch dynamische Stripes haben etc.
ZFS räumt mit Annahmen auf die inzwischen 20 oder 30 Jahre alt sind, es ist komplett neu entwickelt worden mit Blick auf die Computerwelt wie sie heute ist, in der Storagekapazitäten gigantische Ausmaße annehmen und Fehler aufgrund von großen Datendurchsatz sehr leicht auftreten können und möglichst transparent repariert werden sollten. Unter anderem hat ZFS auch die on-disk Struktur stark vereinfacht (Metadaten,inodes welche hier znodes heissen, Daten etc werden gleich behandelt) oder Vorgänge wie formatieren und partitionieren abgeschafft (wer will heute schon 100TB formatieren und auf derartigen Speichermengen noch mit grow und shrink rumhantieren ;) ).
Ergo: Myth BUSTED!
Sehen wir uns erst einmal an wie ein Mirror auf herkömmliche Art und Weise angelegt ist:

Hier liegt eine klassische Trennung von Filesystem und Volumemanager vor. Das Filesystem hat keinerlei Ahnung das es auf einem Mirror arbeitet der Volumemanager liefert ihm einfach ein virtuelles Device und veranstaltet sein spiegeln unbemerkt vom Filesystem. Auf der anderen Seite kennt der Volumemanager sich aber auch nicht mit dem Filesystem aus, er arbeitet einfach nur mit abstrakten Daten die er wegschreibt und er nicht versteht da er keinerlei Bezug zum Filesystem hat.
ZFS ist hier in 3 Schichten aufgeteilt:

Dem ZFS Posix Layer (ZPL) welcher die normale Posix API zur Verfügung stellt (open,close,read,write etc) darunter liegt direkt das ZFS welches einzelne Transaktionen (ZFS arbeitet NUR mit Transaktionen, dass heißt das das Filesystem nie in einen inkonsistenten Zustand kommt) an die Data Management Unit (DMU) weitergibt welche viele Transaktionen zu einer großen zusammenfasst und der Storage Pool Allocator (SPA) welcher Kenntnis von den Platten (die in unserem Beispiel gespiegelt sind) hat.
Jetzt wollen wir als Beispiel auf einem Spiegel einen fehlerhaften Block haben welcher gelesen wird, sagen wir einfach mal es handelt sich hier um Metadaten welche durch äußere Einwirkungen (Erschütterung, Strahlung, statische Entladung etc) verändert wurden. Der Volumemanager hat hier keine Ahnung ob die Daten korrekt sind und reicht sie ans Filesystem weiter. Im schlimmsten Fall kommt es jetzt zu einer Kernelpanic im weniger schlimmen werden falsche Daten gelesen und die Applikation liefert falsche Ergebnisse oder stürzt ab. Da das Filesystem allerdings keinerlei Ahnung hat das es auf einem Mirror arbeitet kann es selbst wenn es bemerkt das die Daten falsch sind ja nicht wissen das evtl ein Mirror mit richtigen Daten existiert und keine korrekten Daten anfordern (da Volumemanager und Filesystem nun einmal voneinander getrennt sind).
Wie macht ZFS das nun? Als Erstes räumt das Design von ZFS mit dem immer noch verbreiteten Glauben auf das Prüfsummen teuer sind. Bei den heuten Rechnergeschwindigkeiten ist die Berechnung einer solchen Summe zeitlich gesehen zu vernachlässigen. Dies macht sich ZFS zu nutze und sichert JEDEN Block mit einer Prüfsumme (default 256-bit). ZFS erkennt also immer ob ein Block immer noch in dem gleichen Zustand auf der Platte liegt wie es ihn geschrieben hat.
Wir lesen nun den gleichen Block aus dem oberen Beispiel noch einmal. Durch die Prüfsumme erkennen wir das der Block falsch ist und da ZFS selber Kenntnis darüber hat das es auf einem Mirror arbeitet fordert es den gleichen Block von der anderen Platte erneut an. Dieser ist in unserem Beispiel korrekt worauf er an die Applikation weitergereicht wird während der andere fehlerhafte Block verworfen wird und mit dem korrekten von der anderen Platte automatisch überschrieben wird. Die Applikation merkt davon nicht das geringste. (Es ist sogar möglich eine der beiden Platte während eines Lese/Schreibvorgangs mit dd if=/dev/random zu überschreiben ohne das die Applikation fehlerhafte Daten zu sehen kriegt, gleichzeitig wird der Schaden den dd anrichtet transparent geheilt)

Hat man nur eine Festplatte zu Verfügung kann man durch zfs set copies=n filesystem veranlassen das alle Datenblöcke n-fach geschrieben werden. Tritt nun ein Fehler auf wird dieser genauso geheilt wie auf einem Mirror. Man kann so ein extra Filesystem für sehr sensible Daten absichern ohne mehrere Platten zur Verfügung zu haben (z.b. auf Notebooks).
Ein anderes beliebtes Beispiel ist der intelligente Prefetchmechanismus. Nehmen wir folgendes an: Auf einem Filesystem liegt eine Videodatei die gleichzeitig von mehreren Benutzern gelesen wird. Alles in allem sind dies sequentielle Lesezugriffe, da alle diese User jedoch eine andere Stelle der Datei lesen kann man hier mit der herkömmlichen Aufteilung kein sequentielles Pattern erkennen, hier kann also kein Prefetch stattfinden da nicht erkannt wird welcher Block als nächstes gelesen wird. Da ZFS allerdings den Userkontext hat kann es erkennen das es sich hier um mehrere sequentielle Reads handelt und dementsprechend optimieren für normale Filesysteme + Volumemanager bleibt dies aufgrund des mangelnden Kontexts eine zufällige Leseabfolge.
Dies sind nur ein paar Beispiele welche Vorteile das Zusammenlegen von Volumemanager und Filesystem hat, unter anderem kann man damit auch dynamische Stripes haben etc.
ZFS räumt mit Annahmen auf die inzwischen 20 oder 30 Jahre alt sind, es ist komplett neu entwickelt worden mit Blick auf die Computerwelt wie sie heute ist, in der Storagekapazitäten gigantische Ausmaße annehmen und Fehler aufgrund von großen Datendurchsatz sehr leicht auftreten können und möglichst transparent repariert werden sollten. Unter anderem hat ZFS auch die on-disk Struktur stark vereinfacht (Metadaten,inodes welche hier znodes heissen, Daten etc werden gleich behandelt) oder Vorgänge wie formatieren und partitionieren abgeschafft (wer will heute schon 100TB formatieren und auf derartigen Speichermengen noch mit grow und shrink rumhantieren ;) ).
Ergo: Myth BUSTED!
Sonntag, 2. November 2008
Die CDDL ist nicht OpenSource?
Anscheinend gibt es immer noch Leute die meinen deratige Parolen schwingen zu müssen (über den Ton den man anderen Personen gegenüber da an den Tag legt will ich hier gar nicht reden). Dabei wiegen Links und andere Beweise wohl anscheinend weniger als "neeeeeeee, wenn ich das sage ist das so". Halten wir die Sache kurz, mit einem Auszug aus der Wikipedia:
Die CDDL wurde am 1. Dezember 2004 der Open Source Initiative zur Abklärung zugesandt und Mitte Januar 2005 für Open-Source-kompatibel befunden. Die CDDL ist auch von der Free Software Foundation (FSF) als freie Lizenz anerkannt.
Und einem Link auf opensource.org.
Langsam nerven diese "heiligen Kriege"...
Die CDDL wurde am 1. Dezember 2004 der Open Source Initiative zur Abklärung zugesandt und Mitte Januar 2005 für Open-Source-kompatibel befunden. Die CDDL ist auch von der Free Software Foundation (FSF) als freie Lizenz anerkannt.
Und einem Link auf opensource.org.
Langsam nerven diese "heiligen Kriege"...
Samstag, 1. November 2008
ZFS: Eine Einführung
Krank sein nervt, aber wenn man im Bett liegt kann man sich mit ein paar Sachen befassen die man sonst eher selten macht. Ich hab die letzten Tage die ich mit Grippe im Bett gelegen hab einfach mal damit verbracht mich in einige ZFS Features einzuarbeiten und mir Gedanken darüber zu machen wie man sie in einem Blog packt. Damit auch die Linuxwelt etwas davon hat hab ich mich auch gleich noch darum gekümmert ZFS unter Ubuntu zum fliegen zu bringen.
Naja lange Rede kurzer Unsinn.
ZFS! Immer wieder hört man das es sich hierbei "nur" um ein Filesystem handelt. Ich will heute mal zeigen das das zwar stimmt, ZFS aber sehr viel mehr ist. Es ist praktisch ein Storage Werkzeugkoffer der fast alles abdeckt was einem in Sachen Storage so über den Weg laufen kann. Das Element mit dem alles anfängt ist der sogenannte zpool. In einem zpool packen wir alles was wir an Storage so nutzen wollen: Festplatte, USB-Sticks, einfach nur Dateien und was weiß ich noch für Devices. Ich werde hier aufgrund eines notorischen Festplattenmangels einfach ganz normale Files nehmen die jeweils 100MB Größe haben.
ZPools
Als erstes werden wir einfach mal die einfachste Sorte von zpools anlegen, nämlich solche die nur aus einem Datenträger bestehen.
Das wars eigentlich schon. Alleine durch die Eingabe von zpool create tank $PWD/disk1 haben wir einen neuen zpool erstellt. Kein formatieren, kein mounten. Das File wurde direkt mit einem ZFS Filesystem auf dem mountpunkt /tank angehängt. Das dauert nur wenige Sekunden.
Was aber machen wenn man mehrere Festplatten hat und deren Platz in einem pool verwenden will?
Wir haben die neue Platte einfach durch add in den zpool eingefügt und wir zpool list zeigt hat sich die Kapazität von tank verdoppelt.
Wir können aber auch zpool mit RAID Fähigkeiten erstellen, dazu gibt es die subkommandos mirror, raidz und raidz2.
Man kann noch sehr viel mehr mit zpools anstellen, aber das reicht fürs erste ;).
Filesysteme
Das erste Filesystem haben wir ja schon mit dem Erstellen des zpools angelegt. Es trägt den Namen tank und ist unter /tank gemountet.
Wir tun jetzt einfach mal so als würden wir eine Art home-Struktur anlegen wollen. Dazu legen wir ein separates home-Filesystem und ein Filesystem für jeden Benutzer an. ZFS Filesysteme sind in etwa vergleichbar mit dem was man unter herkömmlichen Filesystemen als Partitionen bezeichnet, nur das sie sich in ihrer Größe dem Inhalt anpassen. Ein ZFS Filesystem in dem also nichts liegt wird auch praktisch nichts an Plattenplatz belegen.
So wir haben unsere Filesysteme erstellt aber UPS! unsere User sind ja gar nicht an der richtigen Stelle gemountet, eigentlich gehören die ja nach /tank/home. Kein Problem, wir können den Mountpoint im Nachhinein einfach setzen
Das rename ist eigentlich nicht nötig, ich habe es allerdings hier aus Schönheitsgründen mal gemacht ;). Durch das Umsetzen des Mountpoints wird das Filesystem von seinem alten Standort ausgehängt und am neuen Mountpoint eingehängt, alles automatisch.
Wir räumen jetzt einfach mal die anderen Filesysteme weg und arbeiten nur noch mit user1 weiter.
Filesystem Attribute
Jetzt zu ein paar interessanten Attributen die man mit set und get setzen und auslesen kann. Ich werde nur ein paar davon zeigen weil es wirklich eine ganze Menge sind, aber ich halte diese für die praktischsten.
Reservation
Hiermit läßt sich Plattenplatz aus dem zpool reservieren. Dem Filesystem wird also eine bestimmte Menge Storage zugesichert, wie man unten sieht hat tank/home/user1 10MB mehr Speicher zur Verfügung als alle anderen Filesysteme.
Quotas
Was man reservieren kann, kann man aus begrenzen. Mit Quotas lassen sich Filesysteme klein halten.
Compression
Der Name sagt es schon. Filesysteme lassen sich transparent komprimieren. Es gibt unterschiedliche Algorithmen wir nehmen hier gzip als Beispiel.
Hier sollte man daran denken das nur Dateien komprimiert werden die nachträglich im Filesystem erstellt werden. Auch zeigt ls nicht die komprimierte sondern die reale Größe der Datei an.
NFS
Besonders praktisch ist NFS Sharing. Ich werde hier nur die einfachste Form zeigen, aber anstatt on lassen sich die normalen NFS Optionen für das Filesystem angeben. Unter Solaris wird hier alles automatisch eingerichtet und gestartet so das das eingeben einer einzige Zeile reicht um Filesysteme zu sharen (keine Ahnung wie das unter anderem Systemen ist).
Das sind nur ein paar der vielen Attribute die ZFS bietet, alle zu zeigen würden den Rahmen sprengen ;)
Snapshots
Kommen wir zu einem meiner Lieblingsfeatures: Snapshots. Mit Snapshots lassen sich Filesysteme zu einem bestimmten Zeitpunkt einfrieren und auch wieder zurückspielen (und das innerhalb von ein paar Sekunden und ohne das es extra Plattenplatz belegt). Es ist ebenfalls jederzeit möglich in angelegt Snapshots reinzugucken. Wir werden jetzt einfach mal folgendes machen: Wie legen eine Datei mit dem Text "Das ist ein Test" an, danach erstellen wir einen Snapshot und werden die Datei verändern.
Ok wir haben den Zustand unseres Filesystems jetzt unter dem Snapshot mit dem Namen kleinertest gesichert. Nun wollen wir unsere Datei mal kaputtmachen und alles wieder herstellen.
Wie man sieht existiert ein versteckter Ordner .zfs, dieser wird nicht von ls -a angezeigt (Es sei denn man setzt ein bestimmtes Attribut) sondern praktisch on-the-fly erstellt wenn man explizit auf ihn zugreift. Mit zfs rollback spulen wir das Filesystem wieder zu dem Zeitpunkt zurück an dem wir den Snapshot kleinertest erstellt haben (der Snapshot selber existiert weiter). Snapshot sind nicht beschreibbar aber es lassen sich mit zfs clone schreibbare Filesysteme aus einem Snapshot erstellen.
Serialisieren
Ein Filesystem läßt sich in eine einzelne Datei ausgeben die sich dann verschicken läßt und woanders wieder in ein Filesystem umwandeln läßt (sehr praktisch für Backups). Dazu brauchen wir erst einmal einen Snapshot, dieser läßt sich mit zfs send serialisieren und mit zfs receive wieder "entpacken".
Wir haben also nun aus der dump-datei einfach ein neues Userverzeichnis erstellt welches den Zeitpunkt wiederspiegelt an dem wir kleinertest erstellt haben. Snapshots lassen sich auch separat mit zfs list -t snapshot anzeigen
Wie man sieht waren in unserem dump sogar alle Snapshots des Filesystems erhalten (user2 hat ebenfalls einen Snapshot kleinertest)
Import und Export
Filesysteme müssen manchmal mobil sein, z.b. wenn sie auf USB-Sticks liegen. Hierzu kann man zpools einfach exportieren. Exportierte zpools sind ohne das man sie wieder importiert nicht benutzbar (sie werden auch automatisch ausgehängt etc). Steckt man z.b. einen USB-Stick mit einem zpool in das System ein, reicht unter Solaris ein zpool import und alle exportierten Ports werden angezeigt. Ohne Paramter durchsucht dieser Befehl automatisch alle Datenträger nach exportierten zpools im /dev Filesystem.
Da unsere disk Dateien jetzt aber keine echten Devices sind müssen wir den Ort an dem zpool import suchen soll explizit angeben.
Das war ein kleiner aber recht umfangreicher Ausflug in die Welt von ZFS. Und vielen dürfte jetzt klar sein das ZFS mehr ist als nur Volumemanager und Filesystem in einem, es ist ein Storage Verwaltungstools. ZFS ist inzwischen neben Solaris auf FreeBSD, MacOSX und Linux (nur über FUSE) verfügbar. An weiteren Ports wird gearbeitet.
Naja lange Rede kurzer Unsinn.
ZFS! Immer wieder hört man das es sich hierbei "nur" um ein Filesystem handelt. Ich will heute mal zeigen das das zwar stimmt, ZFS aber sehr viel mehr ist. Es ist praktisch ein Storage Werkzeugkoffer der fast alles abdeckt was einem in Sachen Storage so über den Weg laufen kann. Das Element mit dem alles anfängt ist der sogenannte zpool. In einem zpool packen wir alles was wir an Storage so nutzen wollen: Festplatte, USB-Sticks, einfach nur Dateien und was weiß ich noch für Devices. Ich werde hier aufgrund eines notorischen Festplattenmangels einfach ganz normale Files nehmen die jeweils 100MB Größe haben.
ZPools
Als erstes werden wir einfach mal die einfachste Sorte von zpools anlegen, nämlich solche die nur aus einem Datenträger bestehen.
[root@itzkoatl:zfsdemo]> zpool create tank $PWD/disk1
[root@itzkoatl:zfsdemo]> zpool list
NAME SIZE USED AVAIL CAP HEALTH ALTROOT
tank 95.5M 73.5K 95.4M 0% ONLINE -
[root@itzkoatl:zfsdemo]> zpool status tank
pool: tank
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
/export/home/raichoo/zfsdemo/disk1 ONLINE 0 0 0
errors: No known data errors
Das wars eigentlich schon. Alleine durch die Eingabe von zpool create tank $PWD/disk1 haben wir einen neuen zpool erstellt. Kein formatieren, kein mounten. Das File wurde direkt mit einem ZFS Filesystem auf dem mountpunkt /tank angehängt. Das dauert nur wenige Sekunden.
Was aber machen wenn man mehrere Festplatten hat und deren Platz in einem pool verwenden will?
[root@itzkoatl:zfsdemo]> zpool add tank $PWD/disk2
[root@itzkoatl:zfsdemo]> zpool status tank
pool: tank
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
/export/home/raichoo/zfsdemo/disk1 ONLINE 0 0 0
/export/home/raichoo/zfsdemo/disk2 ONLINE 0 0 0
errors: No known data errors
[root@itzkoatl:zfsdemo]> zpool list
NAME SIZE USED AVAIL CAP HEALTH ALTROOT
tank 191M 82.5K 191M 0% ONLINE -
Wir haben die neue Platte einfach durch add in den zpool eingefügt und wir zpool list zeigt hat sich die Kapazität von tank verdoppelt.
Wir können aber auch zpool mit RAID Fähigkeiten erstellen, dazu gibt es die subkommandos mirror, raidz und raidz2.
[root@itzkoatl:zfsdemo]> zpool create tank mirror $PWD/disk1 $PWD/disk2
[root@itzkoatl:zfsdemo]> zpool status tank
pool: tank
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
mirror ONLINE 0 0 0
/export/home/raichoo/zfsdemo/disk1 ONLINE 0 0 0
/export/home/raichoo/zfsdemo/disk2 ONLINE 0 0 0
errors: No known data errors
...
[root@itzkoatl:zfsdemo]> zpool create tank raidz2 $PWD/disk1 $PWD/disk2 $PWD/disk3 $PWD/disk4
[root@itzkoatl:zfsdemo]> zpool status tank
pool: tank
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
raidz2 ONLINE 0 0 0
/export/home/raichoo/zfsdemo/disk1 ONLINE 0 0 0
/export/home/raichoo/zfsdemo/disk2 ONLINE 0 0 0
/export/home/raichoo/zfsdemo/disk3 ONLINE 0 0 0
/export/home/raichoo/zfsdemo/disk4 ONLINE 0 0 0
errors: No known data errors
Man kann noch sehr viel mehr mit zpools anstellen, aber das reicht fürs erste ;).
Filesysteme
Das erste Filesystem haben wir ja schon mit dem Erstellen des zpools angelegt. Es trägt den Namen tank und ist unter /tank gemountet.
[root@itzkoatl:zfsdemo]> zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 98.6K 158M 26.9K /tank
Wir tun jetzt einfach mal so als würden wir eine Art home-Struktur anlegen wollen. Dazu legen wir ein separates home-Filesystem und ein Filesystem für jeden Benutzer an. ZFS Filesysteme sind in etwa vergleichbar mit dem was man unter herkömmlichen Filesystemen als Partitionen bezeichnet, nur das sie sich in ihrer Größe dem Inhalt anpassen. Ein ZFS Filesystem in dem also nichts liegt wird auch praktisch nichts an Plattenplatz belegen.
[root@itzkoatl:zfsdemo]> zfs create tank/home
[root@itzkoatl:zfsdemo]> zfs create tank/user1
[root@itzkoatl:zfsdemo]> zfs create tank/user2
[root@itzkoatl:zfsdemo]> zfs create tank/user3
[root@itzkoatl:zfsdemo]> zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 247K 158M 34.4K /tank
tank/home 26.9K 158M 26.9K /tank/home
tank/user1 26.9K 158M 26.9K /tank/user1
tank/user2 26.9K 158M 26.9K /tank/user2
tank/user3 26.9K 158M 26.9K /tank/user3
So wir haben unsere Filesysteme erstellt aber UPS! unsere User sind ja gar nicht an der richtigen Stelle gemountet, eigentlich gehören die ja nach /tank/home. Kein Problem, wir können den Mountpoint im Nachhinein einfach setzen
[root@itzkoatl:tank]> zfs set mountpoint=/tank/home/user1 tank/user1
[root@itzkoatl:tank]> zfs rename tank/user1 tank/home/user1
[root@itzkoatl:tank]> zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 258K 158M 32.9K /tank
tank/home 55.3K 158M 28.4K /tank/home
tank/home/user1 26.9K 158M 26.9K /tank/home/user1
tank/user2 26.9K 158M 26.9K /tank/user2
tank/user3 26.9K 158M 26.9K /tank/user3
Das rename ist eigentlich nicht nötig, ich habe es allerdings hier aus Schönheitsgründen mal gemacht ;). Durch das Umsetzen des Mountpoints wird das Filesystem von seinem alten Standort ausgehängt und am neuen Mountpoint eingehängt, alles automatisch.
Wir räumen jetzt einfach mal die anderen Filesysteme weg und arbeiten nur noch mit user1 weiter.
[root@itzkoatl:tank]> zfs destroy tank/user2
[root@itzkoatl:tank]> zfs destroy tank/user3
Filesystem Attribute
Jetzt zu ein paar interessanten Attributen die man mit set und get setzen und auslesen kann. Ich werde nur ein paar davon zeigen weil es wirklich eine ganze Menge sind, aber ich halte diese für die praktischsten.
Reservation
Hiermit läßt sich Plattenplatz aus dem zpool reservieren. Dem Filesystem wird also eine bestimmte Menge Storage zugesichert, wie man unten sieht hat tank/home/user1 10MB mehr Speicher zur Verfügung als alle anderen Filesysteme.
[root@itzkoatl:tank]> zfs set reservation=10m tank/home/user1
[root@itzkoatl:tank]> zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 10.2M 148M 28.4K /tank
tank/home 10.0M 148M 28.4K /tank/home
tank/home/user1 26.9K 158M 26.9K /tank/home/user1
Quotas
Was man reservieren kann, kann man aus begrenzen. Mit Quotas lassen sich Filesysteme klein halten.
[root@itzkoatl:tank]> zfs set quota=10m tank/home/user1
[root@itzkoatl:tank]> zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 10.2M 148M 28.4K /tank
tank/home 10.0M 148M 28.4K /tank/home
tank/home/user1 26.9K 9.97M 26.9K /tank/home/user1
Compression
Der Name sagt es schon. Filesysteme lassen sich transparent komprimieren. Es gibt unterschiedliche Algorithmen wir nehmen hier gzip als Beispiel.
[root@itzkoatl:tank]> zfs set compression=gzip tank/home/user1
[root@itzkoatl:tank]> zfs get compression tank/home/user1
NAME PROPERTY VALUE SOURCE
tank/home/user1 compression gzip local
Hier sollte man daran denken das nur Dateien komprimiert werden die nachträglich im Filesystem erstellt werden. Auch zeigt ls nicht die komprimierte sondern die reale Größe der Datei an.
NFS
Besonders praktisch ist NFS Sharing. Ich werde hier nur die einfachste Form zeigen, aber anstatt on lassen sich die normalen NFS Optionen für das Filesystem angeben. Unter Solaris wird hier alles automatisch eingerichtet und gestartet so das das eingeben einer einzige Zeile reicht um Filesysteme zu sharen (keine Ahnung wie das unter anderem Systemen ist).
[root@itzkoatl:tank]> zfs set sharenfs=on tank/home/user1
Das sind nur ein paar der vielen Attribute die ZFS bietet, alle zu zeigen würden den Rahmen sprengen ;)
Snapshots
Kommen wir zu einem meiner Lieblingsfeatures: Snapshots. Mit Snapshots lassen sich Filesysteme zu einem bestimmten Zeitpunkt einfrieren und auch wieder zurückspielen (und das innerhalb von ein paar Sekunden und ohne das es extra Plattenplatz belegt). Es ist ebenfalls jederzeit möglich in angelegt Snapshots reinzugucken. Wir werden jetzt einfach mal folgendes machen: Wie legen eine Datei mit dem Text "Das ist ein Test" an, danach erstellen wir einen Snapshot und werden die Datei verändern.
[root@itzkoatl:user1]> echo "Das ist ein Test" > text
[root@itzkoatl:user1]> ls
text
[root@itzkoatl:user1]> cat text
Das ist ein Test
[root@itzkoatl:user1]> zfs snapshot tank/home/user1@kleinertest
Ok wir haben den Zustand unseres Filesystems jetzt unter dem Snapshot mit dem Namen kleinertest gesichert. Nun wollen wir unsere Datei mal kaputtmachen und alles wieder herstellen.
[root@itzkoatl:user1]> echo "Ich mach alles kaputt!" >| text
[root@itzkoatl:user1]> cat text
Ich mach alles kaputt!
[root@itzkoatl:user1]> cat .zfs/snapshot/kleinertest/text
Das ist ein Test
[root@itzkoatl:user1]> zfs rollback tank/home/user1@kleinertest
[root@itzkoatl:user1]> cat text
Das ist ein Test
Wie man sieht existiert ein versteckter Ordner .zfs, dieser wird nicht von ls -a angezeigt (Es sei denn man setzt ein bestimmtes Attribut) sondern praktisch on-the-fly erstellt wenn man explizit auf ihn zugreift. Mit zfs rollback spulen wir das Filesystem wieder zu dem Zeitpunkt zurück an dem wir den Snapshot kleinertest erstellt haben (der Snapshot selber existiert weiter). Snapshot sind nicht beschreibbar aber es lassen sich mit zfs clone schreibbare Filesysteme aus einem Snapshot erstellen.
Serialisieren
Ein Filesystem läßt sich in eine einzelne Datei ausgeben die sich dann verschicken läßt und woanders wieder in ein Filesystem umwandeln läßt (sehr praktisch für Backups). Dazu brauchen wir erst einmal einen Snapshot, dieser läßt sich mit zfs send serialisieren und mit zfs receive wieder "entpacken".
[root@itzkoatl:user1]> zfs send tank/home/user1@kleinertest > /tank/dump
[root@itzkoatl:user1]> ls -l /tank/dump
-rw-r--r-- 1 root root 15680 Nov 1 17:29 /tank/dump
[root@itzkoatl:user1]> zfs receive tank/home/user2 < /tank/dump
[root@itzkoatl:user1]> cat /tank/home/user2/text
Das ist ein Test
[root@itzkoatl:user1]> zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 10.2M 148M 45.6K /tank
tank/home 10.1M 148M 31.4K /tank/home
tank/home/user1 29.1K 9.97M 29.1K /tank/home/user1
tank/home/user2 27.6K 148M 27.6K /tank/home/user2
Wir haben also nun aus der dump-datei einfach ein neues Userverzeichnis erstellt welches den Zeitpunkt wiederspiegelt an dem wir kleinertest erstellt haben. Snapshots lassen sich auch separat mit zfs list -t snapshot anzeigen
[root@itzkoatl:user1]> zfs list -t snapshot
NAME USED AVAIL REFER MOUNTPOINT
tank/home/user1@kleinertest 0 - 29.1K -
tank/home/user2@kleinertest 0 - 27.6K -
Wie man sieht waren in unserem dump sogar alle Snapshots des Filesystems erhalten (user2 hat ebenfalls einen Snapshot kleinertest)
Import und Export
Filesysteme müssen manchmal mobil sein, z.b. wenn sie auf USB-Sticks liegen. Hierzu kann man zpools einfach exportieren. Exportierte zpools sind ohne das man sie wieder importiert nicht benutzbar (sie werden auch automatisch ausgehängt etc). Steckt man z.b. einen USB-Stick mit einem zpool in das System ein, reicht unter Solaris ein zpool import und alle exportierten Ports werden angezeigt. Ohne Paramter durchsucht dieser Befehl automatisch alle Datenträger nach exportierten zpools im /dev Filesystem.
Da unsere disk Dateien jetzt aber keine echten Devices sind müssen wir den Ort an dem zpool import suchen soll explizit angeben.
[root@itzkoatl:~]> zpool export tank
[root@itzkoatl:~]> zpool import -d ./zfsdemo
pool: tank
id: 14691414290482700440
state: ONLINE
action: The pool can be imported using its name or numeric identifier.
config:
tank ONLINE
raidz2 ONLINE
/export/home/raichoo/zfsdemo/disk1 ONLINE
/export/home/raichoo/zfsdemo/disk2 ONLINE
/export/home/raichoo/zfsdemo/disk3 ONLINE
/export/home/raichoo/zfsdemo/disk4 ONLINE
[root@itzkoatl:~]> zpool import -d ./zfsdemo tank
Das war ein kleiner aber recht umfangreicher Ausflug in die Welt von ZFS. Und vielen dürfte jetzt klar sein das ZFS mehr ist als nur Volumemanager und Filesystem in einem, es ist ein Storage Verwaltungstools. ZFS ist inzwischen neben Solaris auf FreeBSD, MacOSX und Linux (nur über FUSE) verfügbar. An weiteren Ports wird gearbeitet.
ZFS unter Ubuntu Intrepid Ibex
ZFS und Linux ist ja leider ein Thema für sich, aber mit ein paar Handgriffen kann man es sich zumindest so zurechtbiegen das es unter FUSE im Userspace rennt. Auch wenn das nicht gerade die performanteste Lösung auf Erden ist kann man so wenigstens seine zpools unter Linux benutzen.
Um die aktuelle Version 0.5.0 zu kompilieren muss man lediglich die folgenden Pakete nachinstallieren:
build-essential libfuse-dev libaio-dev zlib1g-dev scons
Die aktuelle "ZFS on FUSE" Version findet man hier. Übersetzen und installieren läßt sich das ganze nachdem wir die oben genannten Pakete installiert haben:
Mit sudo zfs-fuse starten wir den Userspace Prozess der ZFS verwaltet.
Leider schmeißt der Code sehr viele Warnings und es ist gleichzeitig das -Werror Flag gesetzt welches ein kompilieren in diesem Fall unmöglich macht. Also entfernen wir dieses Flag aus der src/SConstruct aus dem CFLAGS Eintrage. Das ganze sieht dann so aus:
Ich weiß das ist unschön und gehört eigentlich verboten... vielleicht kennt jemand einen besseren Weg, ich würde mich sehr über Tipps freuen.

Ich plane im Moment eine kleine ZFS Einführung an der jetzt hoffentlich auch die Linuxuser ihren Spaß haben werden.
Um die aktuelle Version 0.5.0 zu kompilieren muss man lediglich die folgenden Pakete nachinstallieren:
build-essential libfuse-dev libaio-dev zlib1g-dev scons
Die aktuelle "ZFS on FUSE" Version findet man hier. Übersetzen und installieren läßt sich das ganze nachdem wir die oben genannten Pakete installiert haben:
raichoo@tensaiga:Projects$ tar xfvj zfs-fuse-0.5.0.tar.bz2
...
raichoo@tensaiga:Projects$ cd zfs-fuse-0.5.0/src
raichoo@tensaiga:Projects$ scons
...
raichoo@tensaiga:Projects$ sudo scons install
Mit sudo zfs-fuse starten wir den Userspace Prozess der ZFS verwaltet.
Leider schmeißt der Code sehr viele Warnings und es ist gleichzeitig das -Werror Flag gesetzt welches ein kompilieren in diesem Fall unmöglich macht. Also entfernen wir dieses Flag aus der src/SConstruct aus dem CFLAGS Eintrage. Das ganze sieht dann so aus:
env['CCFLAGS'] = Split('-pipe -Wall -std=c99 -Wno-switch
-Wno-unused -Wno-missing-braces -Wno-parentheses
-Wno-uninitialized -fno-strict-aliasing -D_GNU_SOURCE
-D_FILE_OFFSET_BITS=64 -D_REENTRANT
-DTEXT_DOMAIN=\\"zfs-fuse\\" -DLINUX_AIO')
Ich weiß das ist unschön und gehört eigentlich verboten... vielleicht kennt jemand einen besseren Weg, ich würde mich sehr über Tipps freuen.

Ich plane im Moment eine kleine ZFS Einführung an der jetzt hoffentlich auch die Linuxuser ihren Spaß haben werden.
Abonnieren
Posts (Atom)